我最近参加了 MLSys 2026 - NVIDIA Track: FlashInfer AI Kernel Generation Contest(FlashInfer Contest, 2026a)。这篇博客并不是一篇关于 CUDA kernel 优化技巧的教程,我本身并不是 GPU 算子开发专家;参加这次比赛的主要目的,是想借助一个高度可验证、反馈明确的任务环境,研究如何让 Coding Agent 在持续闭环中产出高质量的 GPU kernel。
完整材料分为两份报告:Harness Engineering for LLM-Driven GPU Kernel Generation(Shui et al., 2026)和 Full-Agent Kernel Generation for FlashInfer(Ma et al., 2026),代码公开在 mlsys26-flashinfer-contest。
研究背景
大语言模型生成 GPU 内核的难点,不只是写出一段看起来合理的 CUDA/Triton 代码。候选实现必须同时满足语义正确、能够编译、覆盖目标输入形状,并且在真实 GPU 上比已有实现更快。
KernelBench(Ouyang et al., 2025)构建了一个评估框架,让 LLM 读取原始 PyTorch 参考实现,生成自定义内核,然后同时评估编译、正确性和运行性能。
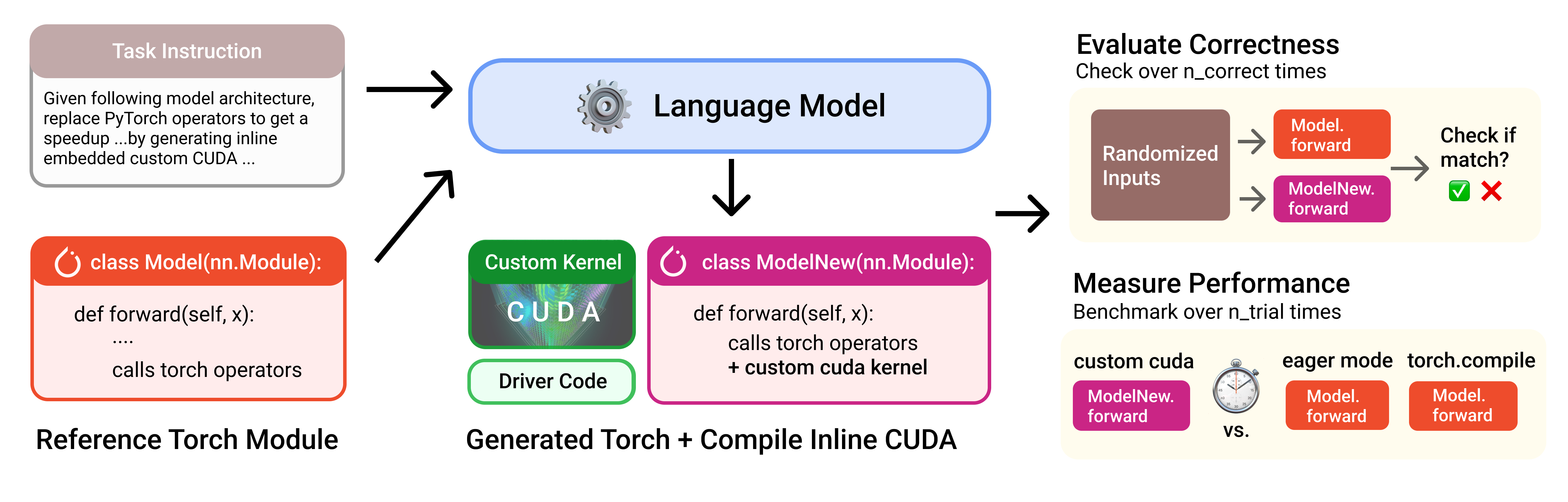
Fig. 1. KernelBench evaluation workflow. A model receives a PyTorch workload, writes a custom kernel implementation, and is evaluated by both functional correctness and latency. (Image source: Ouyang et al., 2025)
FlashInfer-Bench(Xing et al., 2026)进一步把这个问题放到大模型推理服务的真实负载分布中,强调执行轨迹、评测、候选实现和部署之间的闭环。它不是单独的微基准测试,而是要求候选内核在真实推理分布、统一轨迹描述格式和正确性评测下被检验。
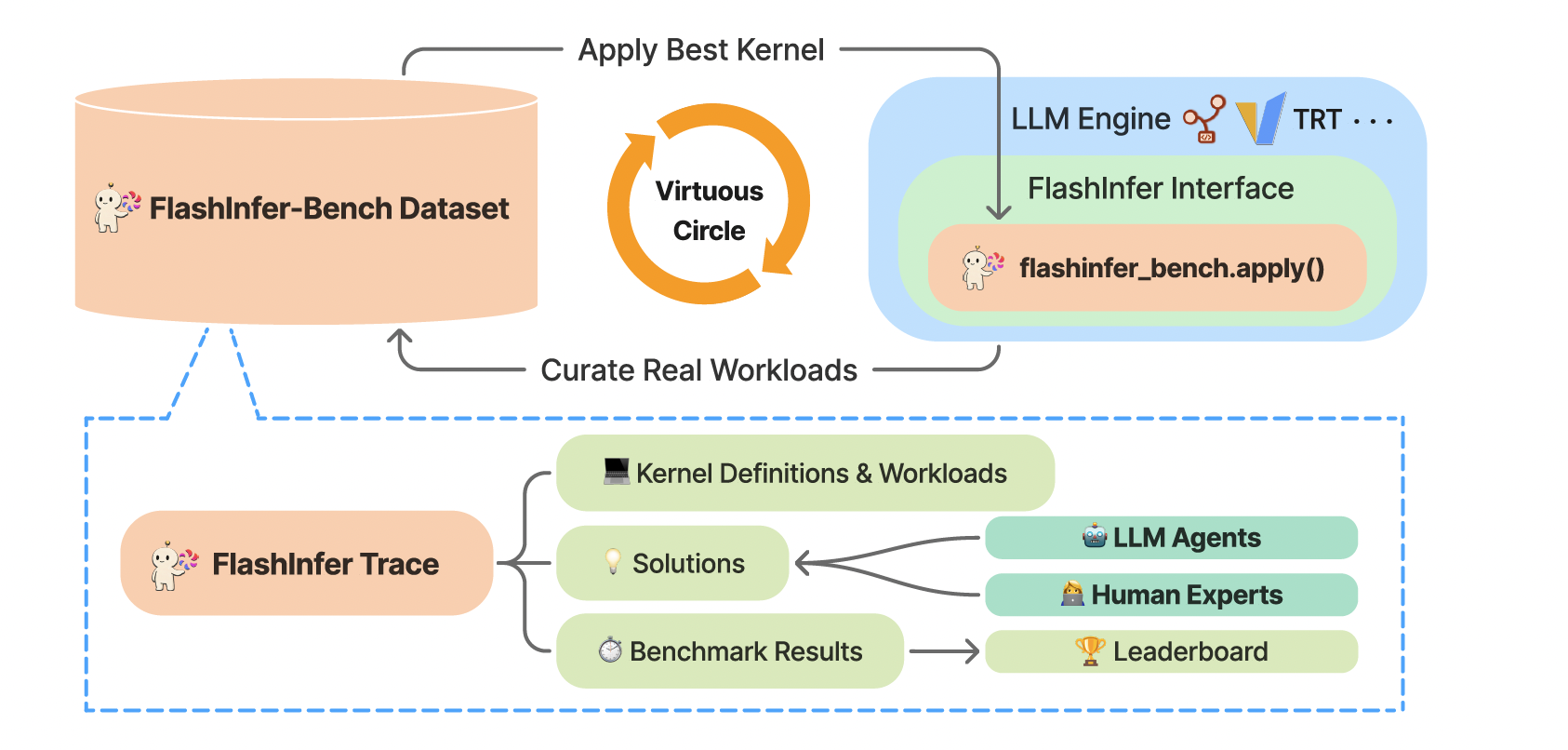
Fig. 2. FlashInfer-Bench architecture. FlashInfer Trace connects kernel definitions, serving workloads, candidate solutions, benchmark results, and deployment paths. (Image source: Xing et al., 2026)
从方法分类看,本文参考综述 Towards Automated Kernel Generation in the Era of LLMs(Yu et al., 2026)的整理,将相关工作概括为 LLM4Kernel 和 Agent4Kernel 两类路线。
LLM4Kernel 基于高质量领域语料,结合 CPT、SFT 和 RL 等训练技术,持续优化模型能力,使其更擅长理解内核开发场景并生成高质量内核代码。
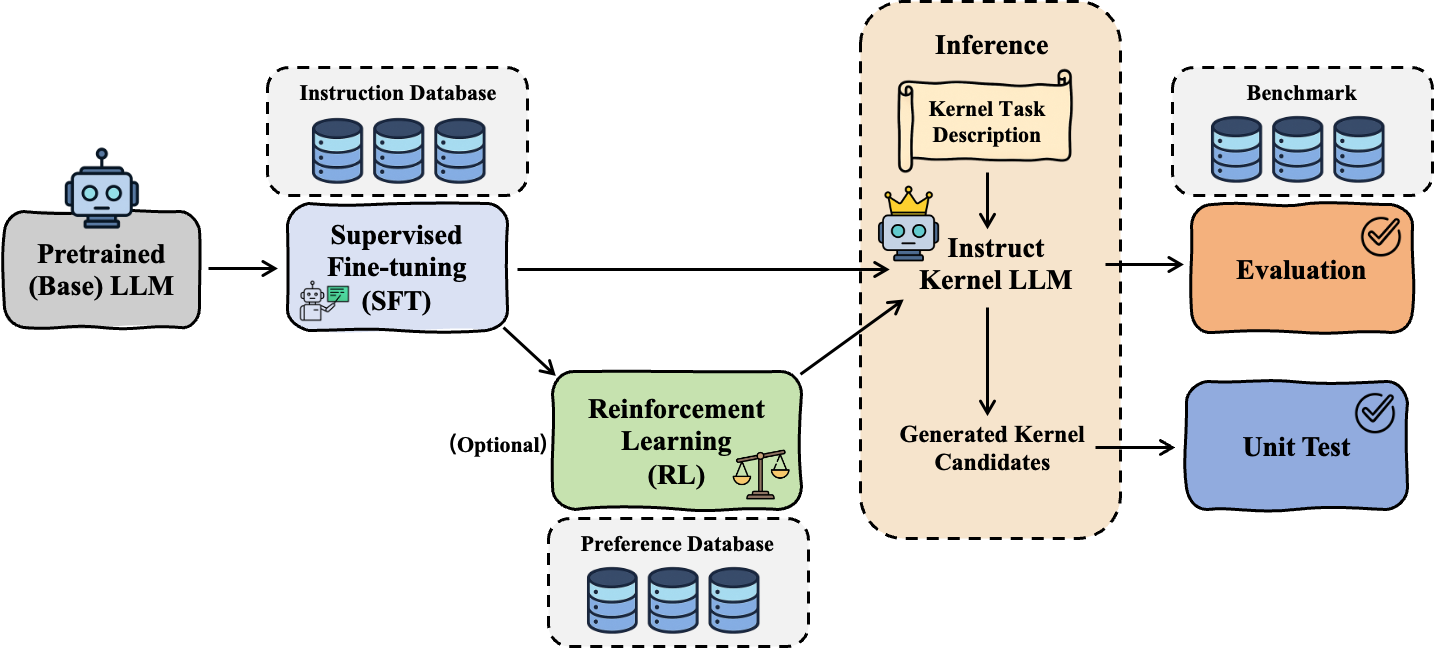
Fig. 3. LLM4Kernel focuses on improving model-side kernel generation capability through data construction, supervised fine-tuning, reinforcement learning, and domain adaptation. (Image source: Yu et al., 2026)
这条路线的优势是可以把内核知识内化到模型参数中,但它通常需要高质量训练数据、稳定的奖励设计和较高训练成本。
Agent4Kernel 则更强调迭代搜索、外部记忆、多智能体编排和自动化评测。我的参赛方案更接近这条路线:不训练一个新模型,而是设计一个让现有代码智能体能持续试错、记录经验并优化实验脚手架的工作流程。
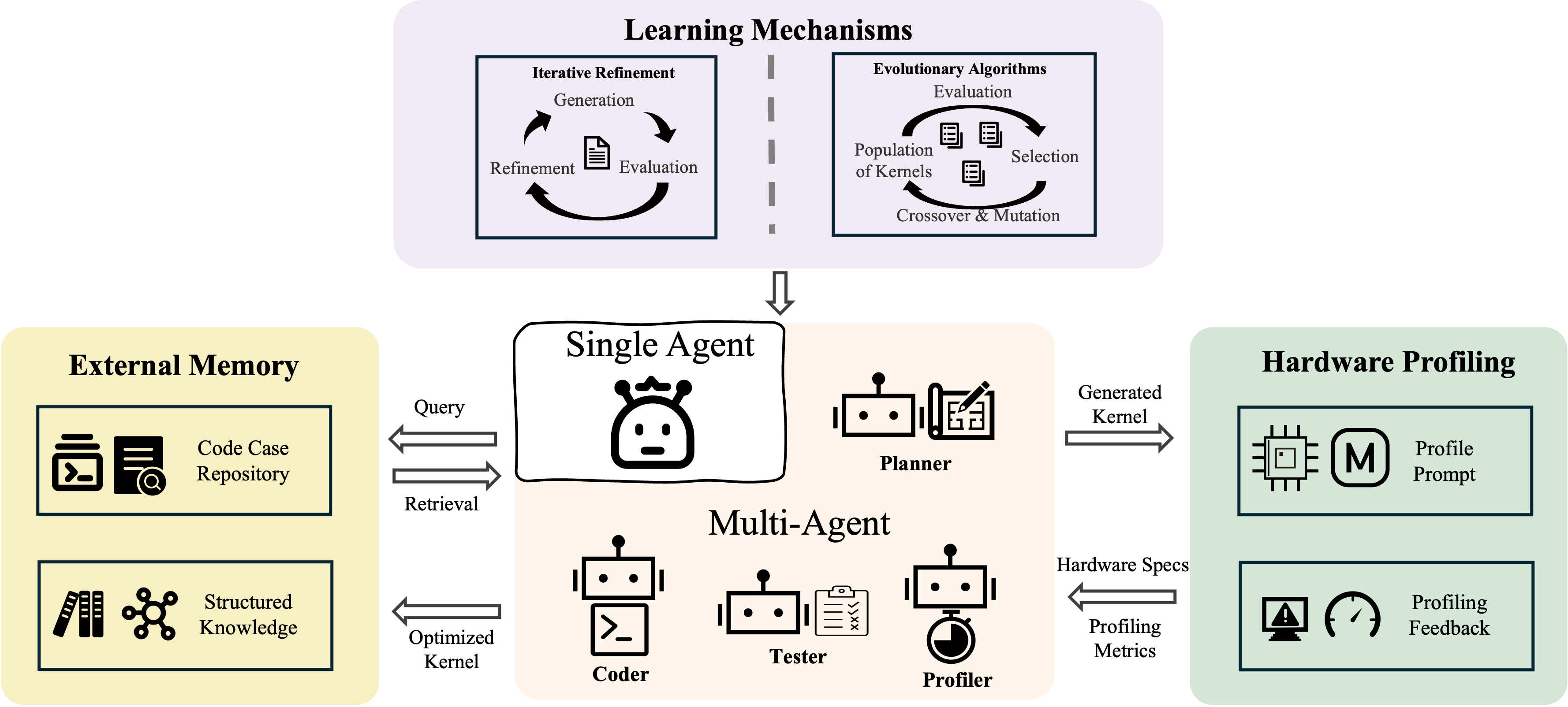
Fig. 4. Agent4Kernel emphasizes iterative refinement, evolutionary search, external memory, hardware profiling, and multi-agent orchestration for kernel optimization. (Image source: Yu et al., 2026)
这种思路也和 Meta 提出的 KernelEvolve(Liao et al., 2025)这样的工业系统相呼应。KernelEvolve 强调持久化知识库、检索增强的提示构造、跨硬件编程抽象,以及面向真实生产算子的持续优化。
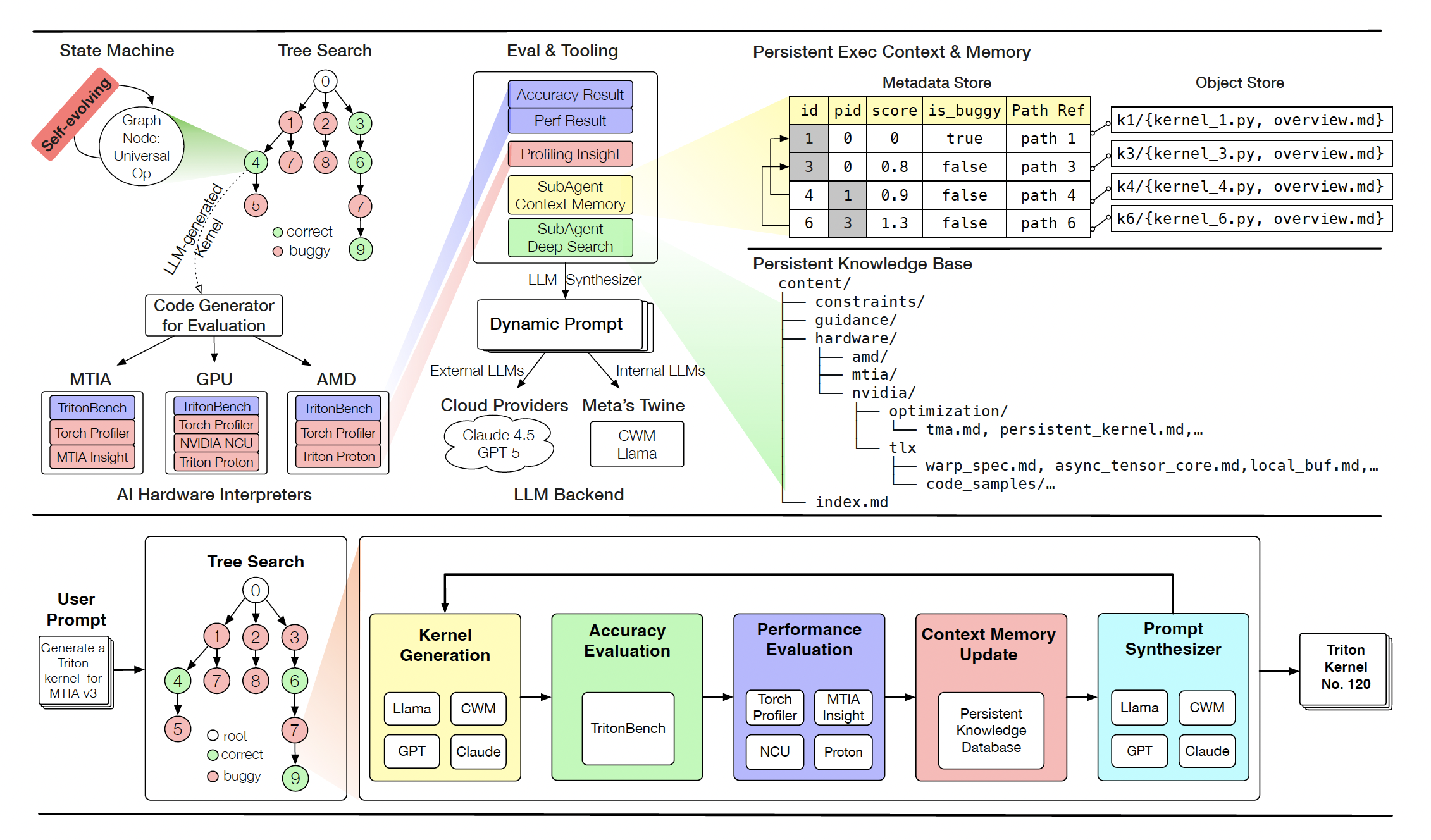
Fig. 5. KernelEvolve system overview. Persistent memory, retrieval, evolutionary search, and hardware-aware evaluation are combined to scale agentic kernel coding to production operators. (Image source: Liao et al., 2025)
GPU 内核智能体的难点是让它在复杂硬件、复杂负载和严格验证约束下保留有效经验,并把失败反馈压缩成下一轮可执行的搜索约束。
方案架构
LLM CUDA 队伍分别提交了 Agent-Assisted 和 Full-Agent 两套路线。它们的区别不在于是否使用 LLM,而在于人类是否持续介入搜索过程。
| 维度 | Agent-Assisted | Full-Agent |
|---|---|---|
| 人类介入 | 人类持续设计策略、提供参考实现、筛选优化方向,并维护晋级规则 | 人类只提供初始任务、约束和自动化工具,后续由智能体自主搜索 |
| 搜索方式 | 根据性能剖析结果和经验选择候选实现家族,优先做有把握的局部优化 | 按“规划、执行、评测、总结、存储”的循环自动展开长程搜索 |
| 状态管理 | 主要依赖人工笔记、技能文件和实验产物归档 | 由 LoongFlow 数据库记录候选来源、结果摘要、当前最优和失败模式 |
Agent-Assisted
Self-Evolving Agents 中讨论过 Harness Engineering(Lopopolo, 2026;Rajasekaran, 2026)的核心范式:人类负责设计约束、构建反馈机制并定义评估标准,Agent 在受控环境内迭代生成更高质量的代码。
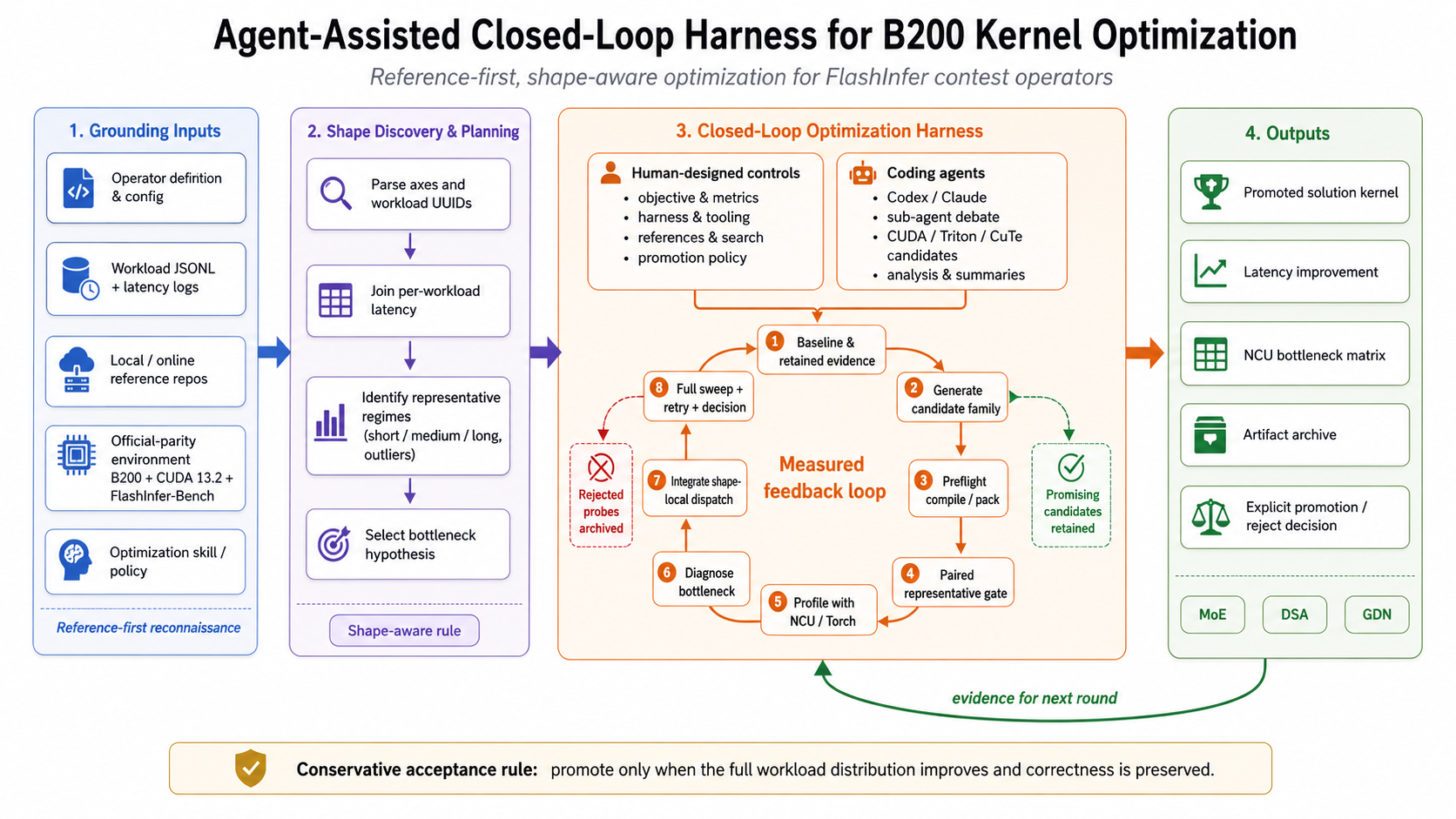
Fig. 6. Agent-Assisted closed-loop harness for B200 kernel optimization. The workflow grounds agents in operator definitions, workload distributions, references, profile signals, and explicit promotion policies. (Image source: Shui et al., 2026)
Agent-Assisted harness 主要分成四层:
- Grounding inputs:算子定义、参考实现和 workload JSON 等必要上下文输入。
- Shape discovery:从 workload 中根据 batch size 和 sequence length 等参数进行分组,并从每组抽取代表性维度,使 agent 可以快速评估和迭代候选,而不需要每次都做全量验证。
- Closed-loop optimization:在 baseline → profile → diagnose → generate → evaluate → archive 这条循环里生成候选,验证代码能否编译、结果是否正确,并评估性能;同时利用 Torch Profiler 和 NVIDIA Nsight Compute (NCU) 等工具分析算子瓶颈。
- Outputs:归档相关代码和性能指标等文件,后续提供给 agent 继续迭代。
人类编写优化 skills、构建评测脚手架。这些做法与 Agent Skills(OpenAI, 2026a)和 Subagents(OpenAI, 2026b)在上下文复用、工具封装和并行探索上的工程动机相似;在本文场景中,它们也帮助把搜索过程约束在可验证的闭环里。
Full-Agent
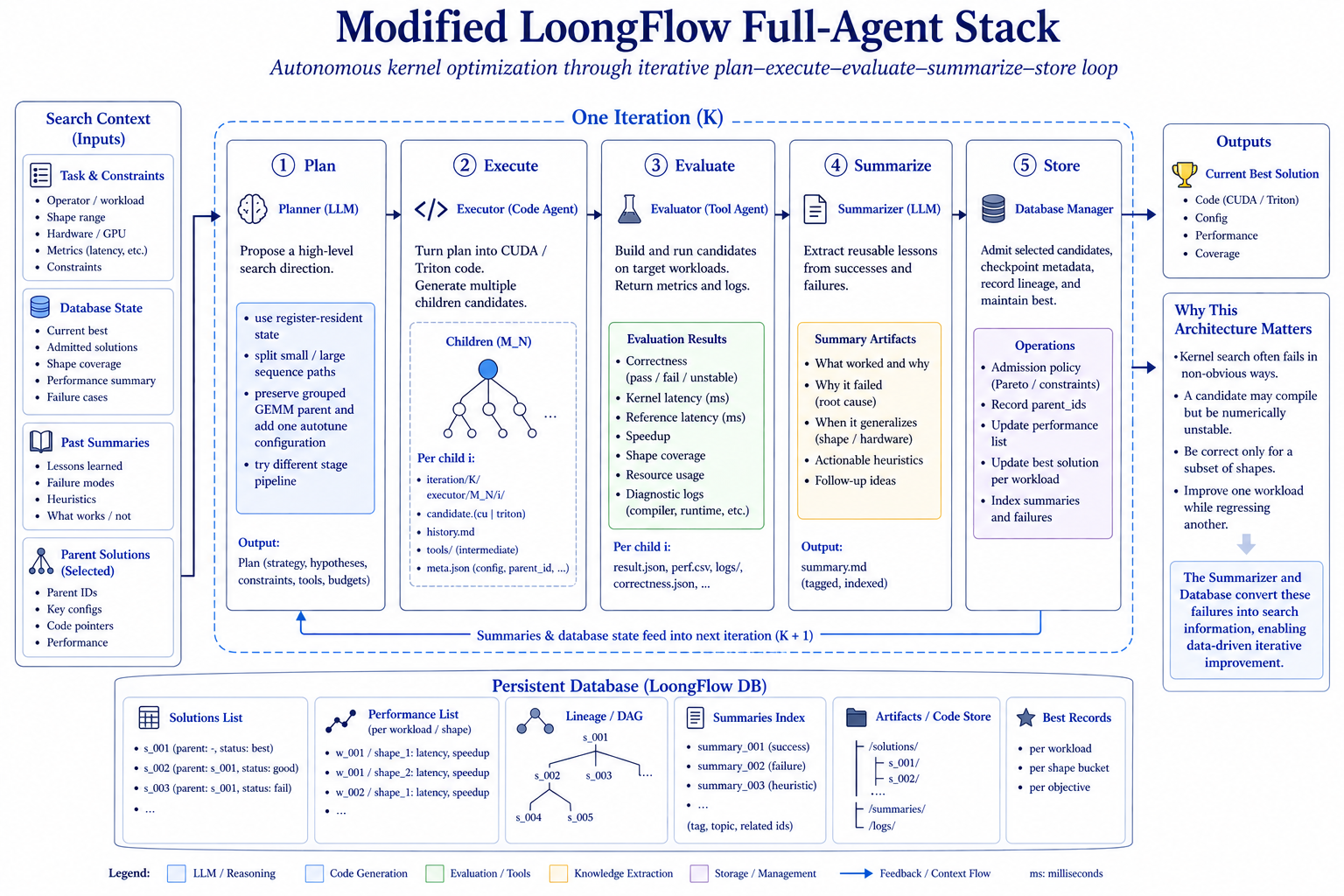
Fig. 7. Modified LoongFlow Full-Agent stack. The agent iterates through planning, code generation, evaluation, summarization, and database updates, turning failed candidates into searchable context for later iterations. (Image source: Ma et al., 2026)
Full-Agent 路线使用框架 LoongFlow(Wan et al., 2025)的计划-执行-总结范式,其类似 OpenEvolve(Sharma, 2025)这类演化搜索系统。它把一次内核搜索拆成规划、执行、评测、总结和存储五步,并把每个候选的来源、性能结果和失败原因等摘要写入持久数据库。
实验结果
官方公布的 Top-3 的 leaderboard 中,我们团队结果如下:
| 官方赛道 | 方法 | 排名 |
|---|---|---|
| Track A Fused MoE | Agent-Assisted | 3rd |
| Track C Gated Delta Net | Agent-Assisted | 3rd |
| Track C Gated Delta Net | Full-Agent | 2nd |
下面的数据来自 Modal 平台 B200 GPU 上的本地评测,结果只适合作参考,因为开发环境的时钟频率不能完全锁定,最终评测运行在 bare-metal 机器上。评测方法参考 FlashInfer(Ye et al., 2025)和 FlashInfer-Bench(Xing et al., 2026)的正确性门控评测设定。下表采用论文中的 matched comparison 口径:延迟为平均毫秒,PyTorch 加速使用对应的 PyTorch reference mean,FlashInfer 加速使用官方提供的 FlashInfer baseline。简化地说,表中的加速比为:
\[ \mathrm{Speedup} = \frac{\mathrm{mean\ baseline\ latency}}{\mathrm{mean\ solution\ latency}}. \]
该表用于分析本地保留产物的优化幅度,并不是官方逐算子或逐赛道 contest score:
| 算子定义 | 方法 | 平均延迟 (ms) | 相对 PyTorch reference mean 加速 | 相对 FlashInfer baseline 加速 |
|---|---|---|---|---|
| DSA Attention | Agent-Assisted | 0.011175 | 217.17× | 29.68× |
| Full-Agent | 0.022811 | 106.39× | 14.54× | |
| FlashInfer baseline | 0.331650 | 7.32× | 1.00× | |
| DSA Indexer | Agent-Assisted | 0.006893 | 494.13× | 18.05× |
| Full-Agent | 0.032659 | 104.29× | 3.81× | |
| FlashInfer baseline | 0.124420 | 27.38× | 1.00× | |
| GDN Prefill | Agent-Assisted | 0.051992 | 21,078× | 13.70× |
| Full-Agent | 0.688875 | 1,591× | 1.03× | |
| FlashInfer baseline | 0.712166 | 1,539× | 1.00× | |
| MoE FP8 | Agent-Assisted | 0.286340 | 63.78× | 1.62× |
| FlashInfer baseline | 0.463874 | 39.37× | 1.00× | |
| Full-Agent | 1.742630 | 10.48× | 0.27× | |
| GDN Decode | Agent-Assisted | 0.006201 | 7,970× | 1.12× |
| FlashInfer baseline | 0.006940 | 7,121× | 1.00× | |
| Full-Agent | 0.008366 | 5,907× | 0.83× |
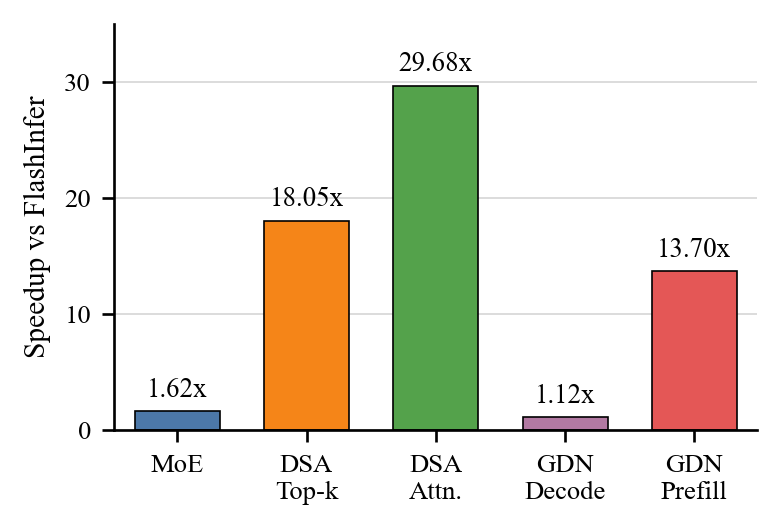
Fig. 8. Final retained speedups over the supplied FlashInfer baseline, measured using mean latency on local Modal B200 runs. (Image source: Shui et al., 2026)
Agent-Assisted 在五个算子上全部优于 FlashInfer baseline,加速比从 1.12×(GDN Decode)到 29.68×(DSA Attention)。Full-Agent 在 DSA Attention、DSA Indexer 和 GDN Prefill 上也找到有效候选,但在 MoE FP8 与 GDN Decode 上低于 baseline。
Agent-Assisted 优化轨迹
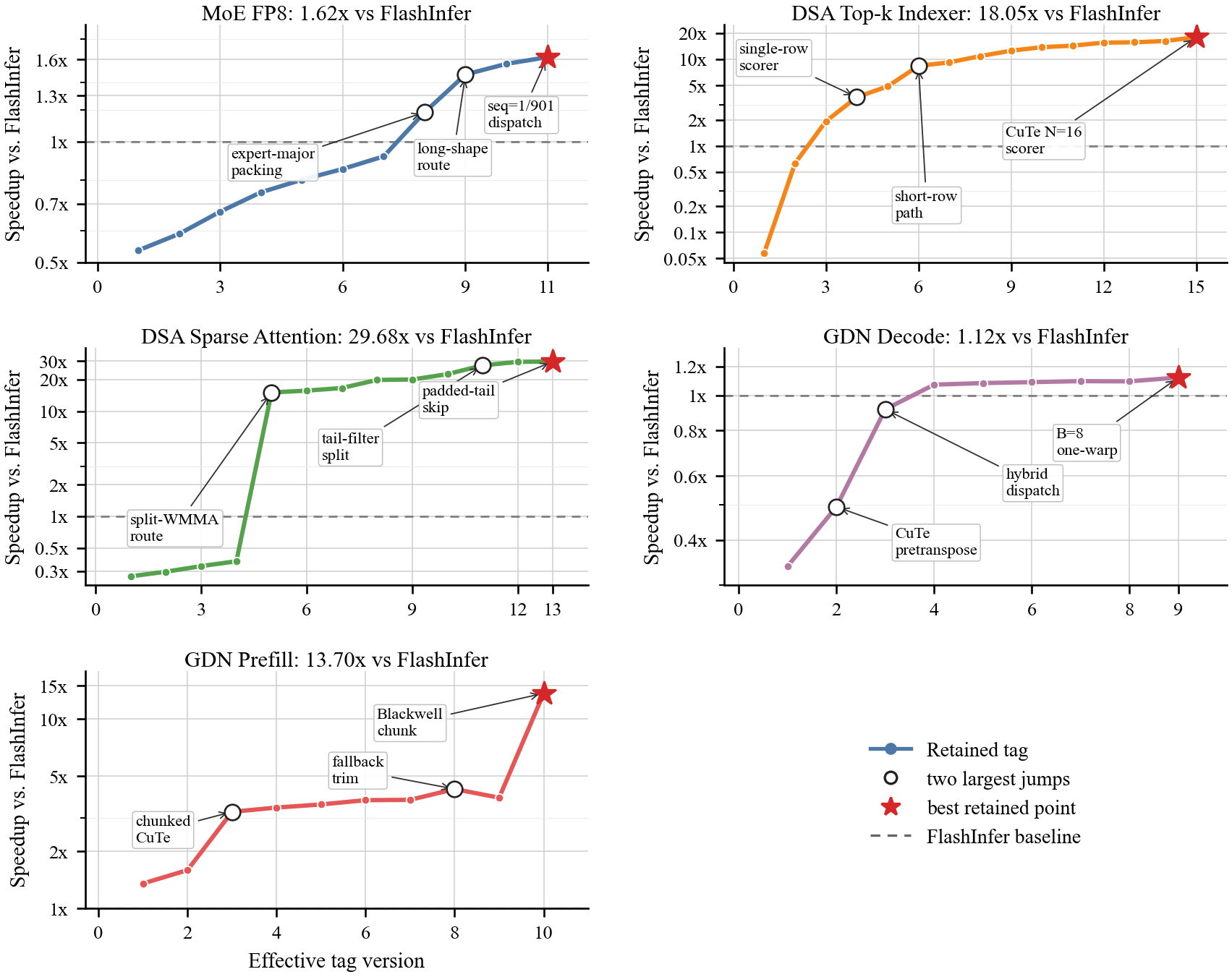
Fig. 9. Retained speedup trajectories over the supplied FlashInfer baseline. The curves show long plateaus and discrete jumps rather than smooth monotonic progress. (Image source: Shui et al., 2026)
从轨迹可以看到,性能提升并不是平滑发生的,而是长期平台期之后出现少数几次明显跃迁。有效的 Agent-Assisted kernel 优化不是单纯依赖提示词,而是依赖可测量的系统闭环:把算子约束、评测脚手架、性能分析反馈和历史轨迹组织成可复用流程,再让智能体在其中生成、验证和保留候选。这个过程需要人类持续设计和维护 harness。
Full-Agent 优化轨迹
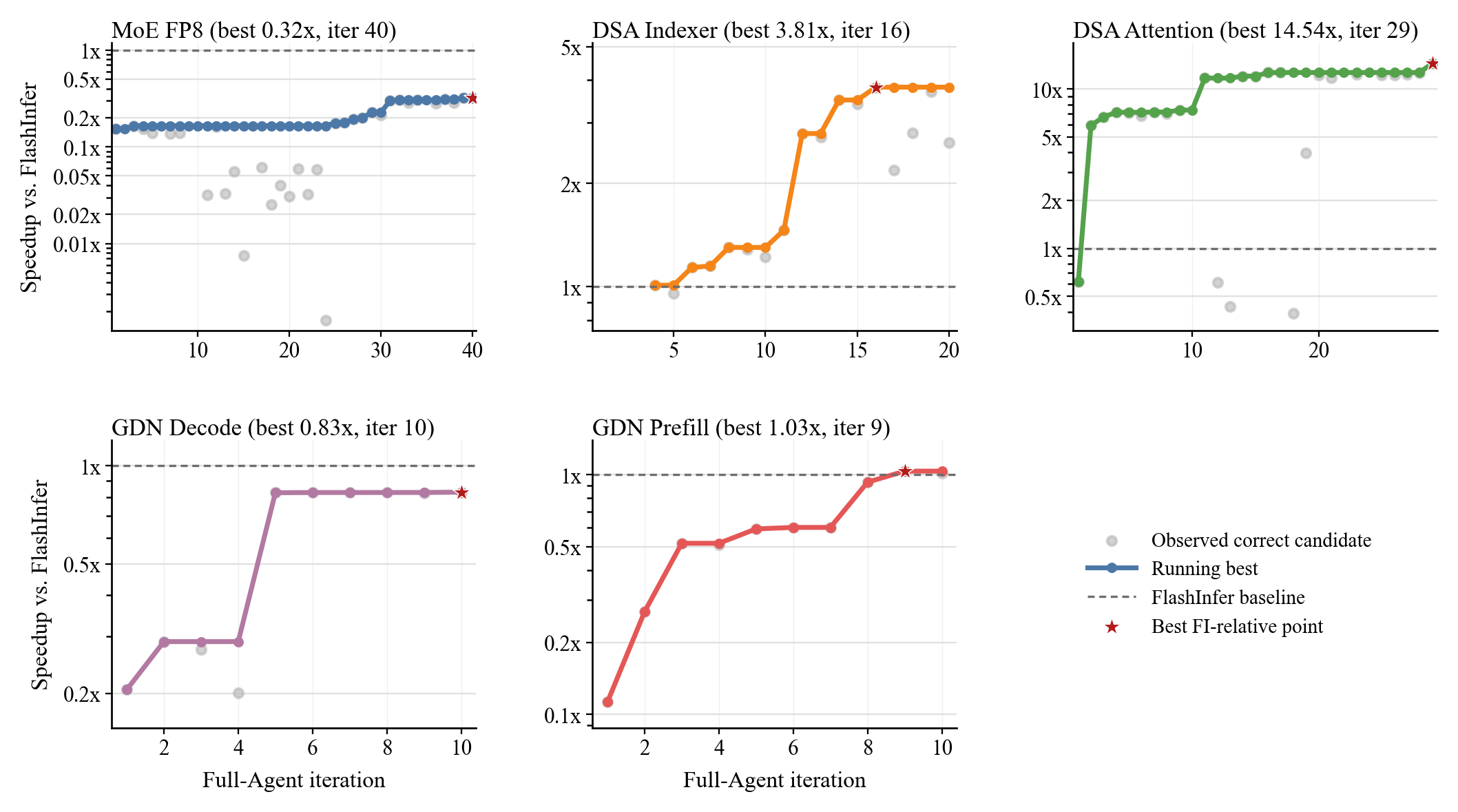
Fig. 10. Full-Agent optimization trajectories from LoongFlow trace logs. Gray dots are correctness-passing candidates, solid lines are running best, and dashed lines mark the FlashInfer baseline. (Image source: Ma et al., 2026)
Full-Agent 轨迹来自自动搜索日志。它也能在部分算子上找到有效候选,例如 DSA Attention 达到 14.54×,但整体仍慢于 Agent-Assisted,并且 MoE FP8 和 GDN Decode 甚至低于 FlashInfer baseline。这个差距说明,完全自动化的智能体搜索仍然困难。人类提供的高质量参考实现和持续积累的轨迹记忆,往往比让智能体从零开始探索更有效率。未来系统需要把控制状态和历史记忆纳入 harness,同时保持严格的最终验证。
未来工作
模型级优化闭环:结合 AutoKernel(Jaber et al., 2026)的思路,把单算子优化扩展到模型级
profile → extract → optimize → verify流程。系统应先用性能剖析器找出模型里的 GPU 瓶颈,再抽取独立 Triton/CUDA 内核,并用 Amdahl’s law 决定下一轮优先优化哪个内核。实验管理与独立验证器:参考官方公开的比赛 writeups(FlashInfer Contest, 2026b),未来的实验脚手架需要固定基准测试、正确性检查、输入形状扫描、数值稳定性、确定性检查、屋顶线分析(Roofline Analysis)、保留/回滚决策和产物结构约束,并使用独立验证器复核候选实现。
负载特化与可检索记忆:高分方案的共同点不是盲目尝试更多 kernel,而是先理解负载分布,再选择适合该分布的实现策略。未来可以把常见负载画像、可复用优化模板、成功候选和失败原因都结构化记录下来,让智能体在生成代码前先检索相似场景,明确适用输入形状、已知瓶颈和不应重复尝试的方向。
参考文献
[1] FlashInfer Contest. “FlashInfer AI Kernel Generation Contest.” MLSys 2026 Competition, NVIDIA Track (2026a).
[2] Shui, Yue, Chenyu Ma, Hangfei Xu, Shengzhao Wen, and Yanpeng Wang. “Harness Engineering for LLM-Driven GPU Kernel Generation.” Technical Report (2026).
[3] Ma, Chenyu, Yue Shui, Hangfei Xu, Shengzhao Wen, and Yanpeng Wang. “Full-Agent Kernel Generation for FlashInfer @ MLSys 2026.” Technical Report (2026).
[4] Ouyang, Anne, et al. “KernelBench: Can LLMs Write Efficient GPU Kernels?” arXiv preprint arXiv:2502.10517 (2025).
[5] Xing, Shanli, et al. “FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems.” arXiv preprint arXiv:2601.00227 (2026).
[6] Yu, Yang, et al. “Towards Automated Kernel Generation in the Era of LLMs.” arXiv preprint arXiv:2601.15727 (2026).
[7] Liao, Gang, et al. “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta.” arXiv preprint arXiv:2512.23236 (2025).
[8] Lopopolo, Ryan. “Harness Engineering: Leveraging Codex in an Agent-First World.” OpenAI Blog (2026).
[9] Rajasekaran, Prithvi. “Harness Design for Long-Running Application Development.” Anthropic Engineering Blog (2026).
[10] OpenAI. “Agent Skills.” OpenAI Developers (2026a).
[11] OpenAI. “Subagents.” OpenAI Developers (2026b).
[12] Wan, Chunhui, et al. “LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm.” arXiv preprint arXiv:2512.24077 (2025).
[13] Sharma, Asankhaya. “OpenEvolve: Open-source Implementation of AlphaEvolve.” GitHub Repository (2025).
[14] Ye, Zihao, et al. “FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving.” Proceedings of Machine Learning and Systems (2025).
[15] Jaber, Jaber, and Osama Jaber. “AutoKernel: Autonomous GPU Kernel Optimization via Iterative Agent-Driven Search.” arXiv preprint arXiv:2603.21331 (2026).
[16] FlashInfer Contest. “MLSys 2026 Contest Writeups.” GitHub Repository (2026b).
引用
引用:转载或引用本文内容时,请注明原作者和来源。
Cited as:
Yue Shui. (May 2026). 基于代码智能体的 GPU Kernel 生成与优化:MLSys 2026 FlashInfer 比赛总结.
https://syhya.github.io/zh/posts/2026-05-18-flashinfer-contest
Or
@article{syhya2026-mlsys26-flashinfer-contest,
title = "基于代码智能体的 GPU Kernel 生成与优化:MLSys 2026 FlashInfer 比赛总结",
author = "Yue Shui",
journal = "syhya.github.io",
year = "2026",
month = "May",
url = "https://syhya.github.io/zh/posts/2026-05-18-flashinfer-contest"
}