大型语言模型(Large Language Models, LLMs)在自然语言处理领域取得了革命性的进展,展现出强大的文本理解和生成能力。然而,LLMs 并非完美无缺,它们仍然面临着一些固有的挑战,例如:
- 知识截止性: LLMs 的知识库通常仅限于其预训练数据,对于训练数据截止日期之后的新信息或事件,它们往往无法准确回答。
- 幻觉: LLMs 有时会“一本正经地胡说八道”,即生成看似合理但实际上是虚假或不准确的信息。
- 领域知识和长尾知识缺乏: 对于特定垂直领域或私有知识库,通用 LLMs 可能缺乏足够的专业知识。相关研究指出 LLMs 在学习长尾知识方面存在困难(Kandpal et al., 2023),而 RAG 可以通过外部知识库在一定程度上缓解这类问题,但效果取决于知识覆盖、索引质量和检索召回。
- 可解释性与可追溯性差: LLMs 的决策过程通常是一个“黑箱”,难以追溯其生成内容的具体来源和依据。
- 上下文窗口限制: LLMs 的上下文窗口长度有限,无法处理过长的输入文本,直接将多个过长的文档输入给 LLM 会导致超过模型的上下文窗口限制,并且推理成本较高。
为了克服这些局限性,检索增强生成(Retrieval-Augmented Generation, RAG) 技术应运而生。Lewis et al. (2020) 最早系统提出将参数化记忆(语言模型参数)与非参数化记忆(外部检索语料)结合的 RAG 框架,并区分了 RAG-Sequence 与 RAG-Token 两类生成方式。今天更常见的工程化 RAG 则通常指在推理时将外部检索结果注入上下文,从而提升模型输出的质量、时效性和可信度。
RAG 基础知识
在深入探讨 RAG 的高级技术之前,我们首先需要理解其基本工作流程和核心组件。一个典型的 RAG 系统主要包含数据处理(或称索引)、检索和生成三个阶段。
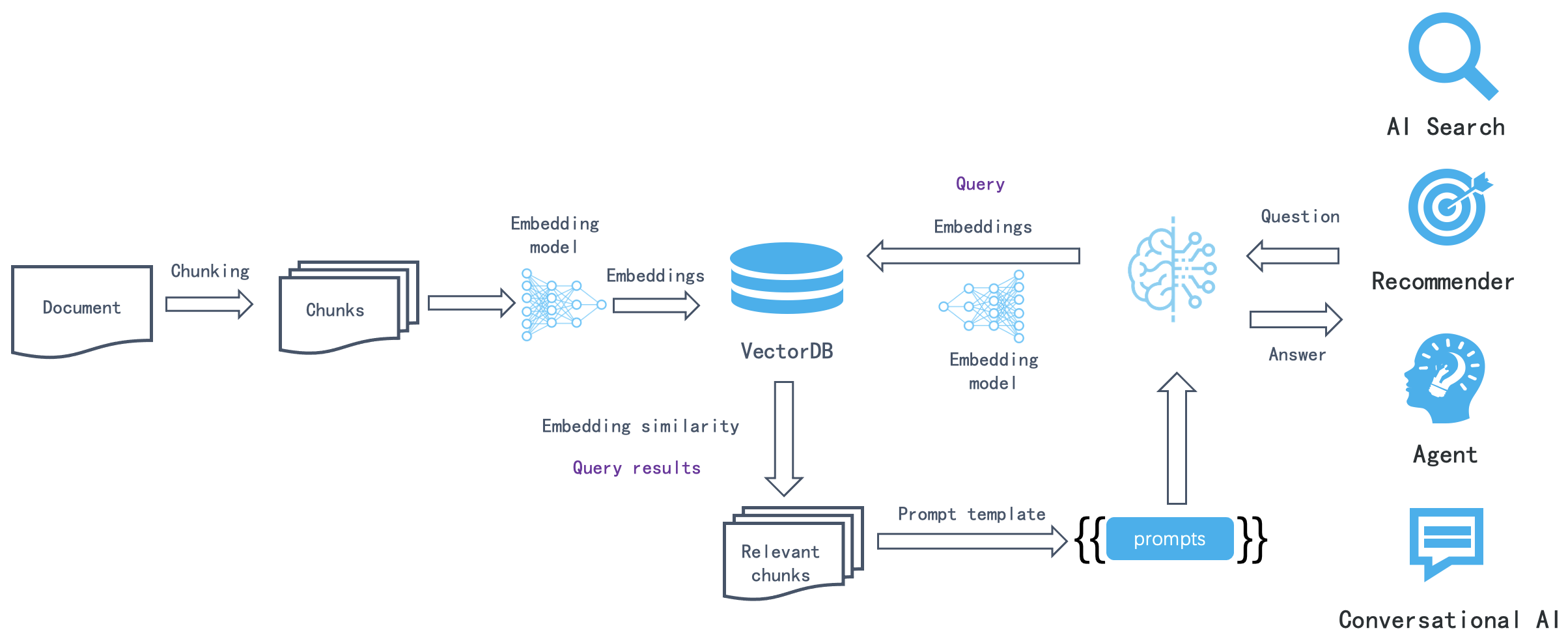
Fig. 1. A representative instance of the RAG process applied to question answering. (Image source: Infinity Blog, 2024)
图 1 展示了一个标准的 RAG 工作流程,其核心思想是在 LLM 生成答案之前,先从外部知识源中检索相关信息,并将这些信息作为上下文提供给 LLM。
1. 数据处理与索引 (Data Processing and Indexing)
RAG 的第一步是准备和处理外部知识源。这些知识源可以是各种形式的文档,如 PDF、网页、数据库记录、代码库、甚至是多模态数据(如图像、音视频)。
- 文档加载 (Document Loading): 从不同的数据源(文件系统、数据库、API、SharePoint 等)加载原始数据。
- 文本分块 (Chunking / Segmentation): 将加载的文档分割成较小的文本块(chunks)。这是因为 LLMs 的上下文窗口长度有限(尽管现代 LLM 的上下文窗口越来越大,如 Gemini 1.5 Pro 的百万级 token 上下文,但过长的上下文仍可能导致中间遗忘问题 (Liu, N. et al., 2024)),并且更小的文本块有助于提高检索的精确度。
- 分块策略 (Chunking Strategies): 常见的策略包括:
- 固定大小分块 (Fixed-size Chunking): 将文本按固定数量的 token 或字符分割。简单但可能切断语义单元。
- 基于字符分块 (Character-based Chunking): 根据特定的字符(如换行符
\n\n、句号.)进行分割。 - 递归分块 (Recursive Character Text Splitting): 尝试按一系列分隔符递归地分割文本,直到块大小满足要求。这有助于保持语义块的完整性,是 LangChain 等框架中常用的方法。
- 语义分块 (Semantic Chunking): 利用 NLP 技术(如句子嵌入、主题模型)来识别文本中的语义边界,并据此进行分块。例如,可以基于句子嵌入的差异来判断语义是否发生较大转变,从而确定分块点。
- 文档特定分块 (Document Specific Chunking): 针对特定文档类型(如 Markdown、HTML、代码文件)的结构进行分块,例如按标题、段落、代码块等。
- 块大小 (Chunk Size): 需要根据具体任务、LLM 的上下文窗口大小、嵌入模型的最佳输入长度以及数据的特性来选择。通常在几百到一千 tokens 之间。
- 重叠 (Overlap): 在相邻块之间设置一定的重叠内容(如 50-100 tokens),以保证语义的连续性,避免关键信息在分块边界被切断。
- 分块策略 (Chunking Strategies): 常见的策略包括:
- 文本嵌入 (Text Embedding): 使用预训练的文本嵌入模型(如 OpenAI 的
text-embedding-3-small/text-embedding-3-large)将每个文本块转换为高维向量。这些向量能够捕捉文本块的语义信息,使得语义相似的文本块在向量空间中距离更近。查询 \( q \) 也会被同一个嵌入模型转换为向量 \( \mathbf{v}_q = E(q) \),而每个文本块 \( c \) 被转换为 \( \mathbf{v}_c = E(c) \)。 - 向量存储与索引 (Vector Storage and Indexing): 将所有文本块的向量表示存储在专门的向量数据库(Vector Database)中。向量数据库不仅存储向量,还为这些向量建立高效的索引,常用的索引算法包括 HNSW、IVF、LSH 等,而 FAISS (Johnson et al., 2019) 和 ScaNN 等是实现这些算法的高性能检索库。常用的向量数据库有 Pinecone, Weaviate, Milvus, ChromaDB, Qdrant, 以及云服务商提供的向量搜索服务(如 Azure AI Search, Google Vertex AI Vector Search, Amazon OpenSearch)。
- 索引类型:
- Flat: 精确搜索,但对于大规模数据效率较低。
- IVF (Inverted File Index): 通过聚类将向量分组,搜索时只在相关的簇内进行。
- HNSW (Hierarchical Navigable Small World): 基于图的索引,通过构建多层图结构实现高效的近似最近邻搜索。
- LSH (Locality Sensitive Hashing): 通过哈希函数将相似的向量映射到相同的桶中。
- 索引类型:
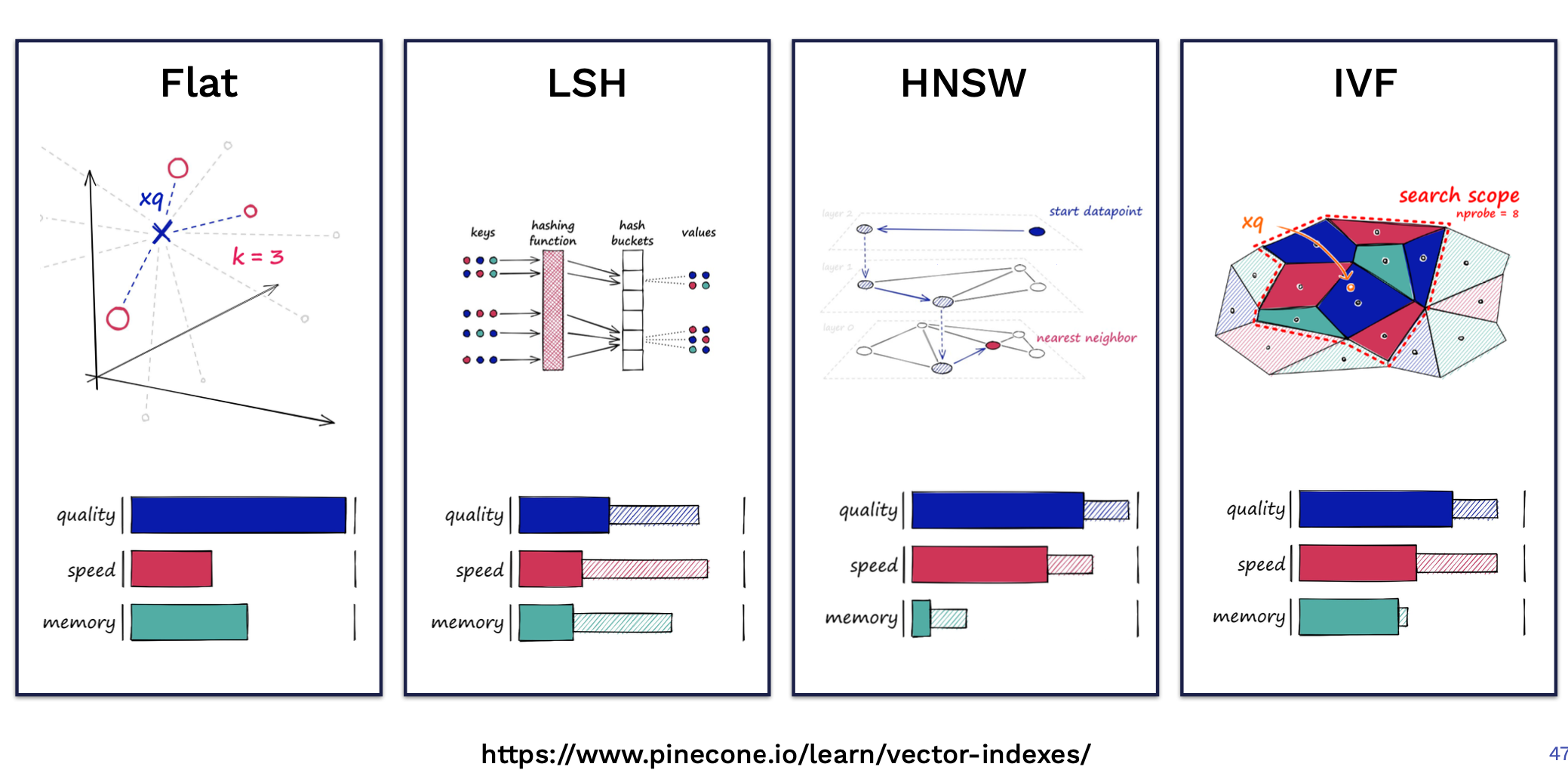
Fig. 2. Comparison of different ANN algorithms: Flat, LSH, HNSW, IVF. (Image source: Pinecone)
图 2 展示了几种常见的向量索引类型及其在检索质量、速度和内存消耗方面的权衡。
2. 检索 (Retrieval)
当用户提出一个查询 \( q \) 时,RAG 系统会执行以下检索步骤:
- 查询嵌入 (Query Embedding): 使用与文档处理阶段相同的嵌入模型将用户查询 \( q \) 转换为查询向量 \( \mathbf{v}_q \)。
- 相似性搜索 (Similarity Search): 在向量数据库中,利用索引结构高效地查找与查询向量 \( \mathbf{v}_q \) 最相似的文本块向量 \( \mathbf{v}_c \)(实际使用 ANN 算法避免逐一比较)。最常用的相似度度量是余弦相似度 (Cosine Similarity):
$$
\text{sim}(\mathbf{v}_q, \mathbf{v}_c) = \frac{\mathbf{v}_q \cdot \mathbf{v}_c}{\|\mathbf{v}_q\| \|\mathbf{v}_c\|}
$$
其中 \( \cdot \) 表示向量点积,\( \|\cdot\| \) 表示向量的欧几里得范数(L2 范数)。其他相似度度量还包括:
- 点积 (Dot Product / Inner Product): \( S_{\text{dot}}(\mathbf{v}_q, \mathbf{v}_c) = \mathbf{v}_q \cdot \mathbf{v}_c \)。如果向量已归一化,则等价于余弦相似度。
- 欧氏距离 (Euclidean Distance / L2 Distance): \[ \begin{aligned} L_2(\mathbf{v}_q, \mathbf{v}_c) &= \|\mathbf{v}_q - \mathbf{v}_c\| \\ &= \sqrt{\sum_{i=1}^{n} (v_{q_i} - v_{c_i})^2} \end{aligned} \] 距离越小表示越相似。
- 上下文选择 (Context Selection): 选择与查询向量最相似的 \( K \) 个文本块 \( \{C_1, C_2, \ldots, C_K\} \) 作为增强 LLM 上下文的背景知识。\( K \) 值的选择是一个超参数,需要根据任务和 LLM 的上下文窗口大小进行调整。
3. 生成 (Generation)
检索到相关的文本块后,RAG 系统将这些信息与原始用户查询结合起来,输入给 LLM 以生成最终答案:
- 提示构建 (Prompt Engineering): 将用户查询 \( q \) 和检索到的 \( K \) 个文本块 \( \{C_1, \ldots, C_K\} \) 组合成一个结构化的提示 \( P \)。一个常见的提示模板如下:提示的设计对 RAG 系统的性能至关重要。
请根据以下提供的上下文信息来回答用户的问题。如果上下文信息不足以回答问题,请明确指出。 上下文信息: --- [上下文块 1: C_1 的内容] --- [上下文块 2: C_2 的内容] --- ... --- [上下文块 K: C_K 的内容] --- 用户问题:[用户查询 q 的内容] 答案: - LLM 推理 (LLM Inference): 将构建好的提示 \( P \) 输入给 LLM,LLM 会基于其预训练知识和提供的上下文信息生成答案 \( A = \text{LLM}(P) \)。
通过这种方式,RAG 系统能够利用外部知识库的最新和特定领域信息来增强 LLM 的回答,从而提高答案的准确性、相关性和时效性。
RAG 的技术定位:与模型微调的对比
在将领域知识融入 LLM 时,RAG 和模型微调 (Fine-tuning, FT) 是两种主要的技术路径。它们各有优劣,适用于不同的场景。
| 特性 | RAG (检索增强生成) | 模型微调 (Fine-tuning) |
|---|---|---|
| 知识更新 | 近实时,通过更新外部知识库实现(需维护索引管道) | 滞后,需要重新训练模型以融入新知识 |
| 计算成本 | 推理时有检索开销;知识库构建成本相对较低 | 训练成本高昂,尤其对于大型模型;推理成本固定 |
| 幻觉问题 | 可显著减少(取决于检索质量和上下文相关性) | 仍可能存在,尤其对于训练数据未覆盖的知识 |
| 可解释性 | 较高,可以追溯答案来源 | 较低,模型决策过程不透明 |
| 领域适应性 | 强,易于接入不同领域的知识库 | 强,模型可以深度学习特定领域的语言模式和知识 |
| 数据隐私 | 知识库可保持私有;但使用托管 LLM 时,检索片段仍会进入 prompt | 训练数据可能需要上传给模型服务提供商,存在隐私风险 |
| 实现复杂度 | 相对较高,需要构建和维护检索系统 | 较高,需要准备高质量的微调数据集和专业的训练技巧 |
| 适用场景 | 动态知识、事实问答、需要溯源的场景、减少幻觉 | 学习特定风格、语气、格式,或深度掌握特定领域知识的场景 |
在许多实际应用中,RAG 和微调并非互斥,而是可以结合使用。例如,可以先对 LLM 进行领域相关的微调,使其更好地理解领域术语和概念,然后再结合 RAG 来获取最新的动态信息。
RAG 的核心技术与范式演进
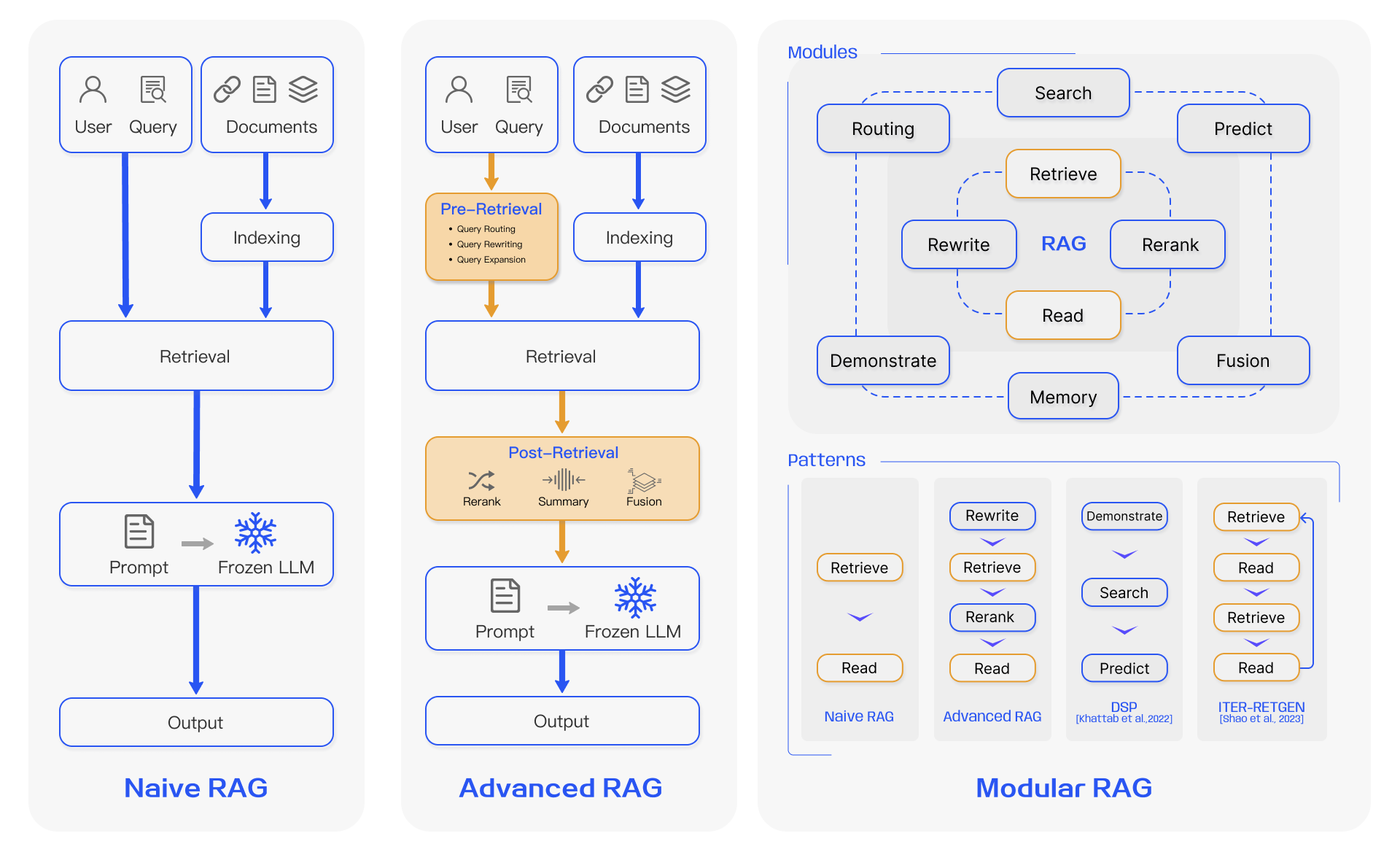
Fig. 3. The Evolution of RAG paradigms: Naive RAG, Advanced RAG, and Modular RAG. (Image source: Gao et al., 2024)
图 3 展示了 RAG 范式从朴素 RAG 到高级 RAG 再到模块化 RAG 的演进过程。理解这些演进有助于我们更好地设计和优化 RAG 系统。
1. 朴素 RAG (Naive RAG)
朴素 RAG 是 RAG 技术最基础的形态,遵循上一节所述的“索引-检索-生成”线性模式。其主要局限性包括:
- 检索质量: 低精确率(噪声过多)、低召回率(遗漏关键信息)、过时信息。
- 生成质量: 幻觉、不连贯/重复、上下文整合不佳。
- 增强过程: 分块策略选择困难、上下文窗口限制、成本与延迟。
2. 高级 RAG (Advanced RAG)
为了克服朴素 RAG 的局限性,研究者们提出了多种高级 RAG 技术,主要围绕优化检索和生成过程展开。
2.1 优化检索过程 (Optimizing Retrieval)
提升检索质量是高级 RAG 的核心目标之一。
预检索策略 (Pre-retrieval Strategies): 这些策略在实际检索发生之前对数据或查询进行优化。
- 数据清洗与优化 (Data Cleaning and Optimization):
- 数据清洗: 去除无关字符、格式化文本、处理噪声数据。
- 元数据提取与增强 (Metadata Extraction and Enrichment): 从文档中提取结构化信息(如标题、作者、日期、章节、关键词、文件来源、上次修改时间等)作为元数据,并在检索时用于过滤或加权。例如,可以根据文档的创建日期过滤掉过时的信息,或者优先检索来自特定作者的文档。
- 信息提取与结构化: 将非结构化文本中的关键信息(如实体、关系)提取出来,并可能将其转换为结构化格式(如知识图谱节点/边),以便后续更精确的检索。
- 索引结构优化 (Index Structure Optimization):
- 分块策略优化 (Chunking Strategy Optimization):
- 内容感知分块 (Content-aware Chunking): 例如,基于 NLP 的句子分割、段落分割,或者使用 LLM 来判断最佳分块点。LlamaIndex 中的
SemanticSplitterNodeParser是一种尝试。 - 滑动窗口 (Sliding Window): 在文本切分时,采用重叠的滑动窗口,以避免重要信息在块边界被切断。
- 小块到大块 (Small-to-Big / Parent Document Retriever): 索引较小的、更具针对性的文本块,但在检索到这些小块后,将其父文档或更大的上下文窗口提供给 LLM。这有助于平衡检索精度和上下文完整性。LangChain 中的
ParentDocumentRetriever就是一个例子。 - 摘要嵌入 (Summary Embedding / Proposition Indexing): 为每个文档或大块文本生成摘要或原子性的命题(propositions),然后对摘要/命题进行嵌入和索引。检索时先匹配摘要/命题,再定位到原始文档或相关块。DenseX (Chen et al., 2023) 提出使用命题作为检索单元。
- 内容感知分块 (Content-aware Chunking): 例如,基于 NLP 的句子分割、段落分割,或者使用 LLM 来判断最佳分块点。LlamaIndex 中的
- 多向量检索器 (Multi-Vector Retriever): 为同一个文档块生成多个向量表示,以从不同角度捕捉其语义。例如:
- 小块向量: 将文档分割成更小的子块,为每个子块生成向量。
- 摘要向量: 为文档块生成摘要,并对摘要进行嵌入。
- 假设性问题向量 (Hypothetical Questions): 为每个文档块生成一些可能由该块回答的问题,然后对这些问题进行嵌入。检索时,将用户查询与这些假设性问题进行匹配。
- 分块策略优化 (Chunking Strategy Optimization):
- 查询优化 (Query Optimization):
- 查询扩展 (Query Expansion): 使用同义词、相关术语、LLM 生成的多个查询变体或子问题来扩展原始查询,以召回更全面的相关文档 (Jagerman et al., 2023)。Query2Doc (Wang, L. et al., 2023) 使用 LLM 生成伪文档来扩展查询。
- 查询转换/重写 (Query Transformation/Rewriting): 利用 LLM 将用户的原始查询重写为更清晰、更适合检索的表达形式。例如,去除歧义、补充上下文、明确意图。Rewrite-Retrieve-Read (Ma et al., 2023) 框架就是一个例子。
- 查询路由 (Query Routing): 根据查询的类型或意图,将其路由到不同的索引、数据源或检索策略。例如,事实性问题可能路由到向量索引,而分析性问题可能需要更复杂的检索流程或知识图谱查询。
- HyDE (Hypothetical Document Embeddings) (Gao et al., 2023): LLM 根据用户查询生成一个假设性的答案文档 \(D_{hypo}\)。然后,使用 \(D_{hypo}\) 的嵌入 \( \mathbf{v}_{D_{hypo}} = E(D_{hypo}) \) 来检索真实的文档块。这种方法认为,与查询直接相关的文档,其语义可能更接近于一个理想的答案,而不是查询本身。
- 步退提示 (Step-Back Prompting) (Zheng et al., 2024): 对于特定、细节性的问题,先让 LLM 生成一个更泛化、更高层次的“步退问题”,然后检索与这个步退问题相关的上下文,再结合原始问题进行回答。这有助于获取更全面的背景知识。
- 数据清洗与优化 (Data Cleaning and Optimization):
检索中策略 (During-retrieval Strategies): 这些策略在检索过程中动态调整。
- 嵌入模型微调 (Fine-tuning Embedding Models): 在特定领域的数据集或与任务相关的查询-文档对上微调嵌入模型。可以使用对比学习损失(如 InfoNCE)来拉近相关对的距离,推远不相关对的距离。 $$ \mathcal{L}_{\text{InfoNCE}} = -\log \frac{\exp(\text{sim}(\mathbf{v}_Q, \mathbf{v}_{C^+}) / \tau)}{\sum_{i=0}^{N} \exp(\text{sim}(\mathbf{v}_Q, \mathbf{v}_{C_i}) / \tau)} $$ 其中 \( \mathbf{v}_{C^+} \) 是与查询 \( \mathbf{v}_Q \) 相关的正例文本块嵌入,分母中的求和遍历所有候选样本(包含 1 个正例和 \( N \) 个负例,通常包括批内负例和难负例),\( \tau \) 是温度超参数。BGE M3-Embedding (Chen et al., 2024) 通过自知识蒸馏和高效批处理策略训练多语言、多功能、多粒度的文本嵌入。
- 混合检索 (Hybrid Search): 结合稀疏检索(如 BM25,基于词频统计)和稠密检索(向量检索,基于语义相似性)的结果。通常通过对两种检索器的得分进行加权求和或使用更复杂的融合策略(如 Reciprocal Rank Fusion, RRF)来实现。
后检索策略 (Post-retrieval Strategies): 这些策略在检索到初步结果后进行优化。
- 重排序 (Re-ranking): 对初步检索到的 \( K \) 个文本块进行二次排序,以提高排序顶部的相关性。
- 基于模型的重排序: 使用更强大的模型(如 Cross-Encoder,它将查询和每个文档块拼接后输入模型进行打分,计算成本较高但通常更准确)或专门的重排序模型(如 Cohere Rerank, bge-reranker-large)。
- 基于 LLM 的重排序: 提示 LLM 对检索到的文本块列表进行相关性打分或排序。
- 上下文压缩与选择 (Context Compression and Selection):
- LLMLingua (Jiang, H. et al., 2023): 使用小型 LLM 来识别和移除提示中的冗余词元,从而在保持关键信息的同时压缩上下文长度,减少 LLM 推理成本和延迟。
- 选择性上下文 (Selective Context): 根据某些启发式规则或小型模型来选择最重要的文本块或句子,而不是使用所有检索到的内容。
- 信息过滤: 过滤掉与查询主题无关或质量较低的检索结果。FILCO (Wang, Z. et al., 2023) 学习过滤上下文以增强 RAG。
- RECOMP (Retrieve, Compress, Prepend) (Xu et al., 2024): 检索文档后,使用 LLM 将其压缩成摘要,然后将摘要添加到原始查询前,再输入给 LLM 生成答案。
- 重排序 (Re-ranking): 对初步检索到的 \( K \) 个文本块进行二次排序,以提高排序顶部的相关性。
2.2 优化生成过程 (Optimizing Generation)
除了优化检索,提升 LLM 在 RAG 框架下的生成能力也至关重要。
- LLM 微调 (Fine-tuning LLMs for RAG):
- 特定任务微调: 在包含“上下文-查询-答案”三元组的数据集上微调 LLM,使其更擅长利用检索到的上下文来回答问题。RETRO (Borgeaud et al., 2022) 就是一个在预训练阶段就进行检索增强的例子。RA-DIT (Lin et al., 2024) 提出了一种检索增强的双指令微调方法。
- 指令微调 (Instruction Tuning): 使用包含各种指令的数据集进行微调,使 LLM 更好地遵循 RAG 流程中的指令(如“根据以下上下文回答问题”)。
- 提示工程 (Prompt Engineering for RAG):
- 结构化提示: 精心设计提示的结构,清晰地分隔查询、上下文和生成指令。
- 角色扮演: 指示 LLM 扮演特定角色(如“你是一个乐于助人的 AI 助手”)。
- 思维链提示 (Chain-of-Thought Prompting, CoT): 引导 LLM 在生成答案前先进行一步步的推理。IRCoT (Trivedi et al., 2023) 将 CoT 与检索交错进行。
- 处理噪声和矛盾: 在提示中加入如何处理上下文中噪声或矛盾信息的指令。
- 引用来源: 要求 LLM 在答案中明确指出信息的来源(来自哪个检索到的文本块)。
3. 模块化 RAG (Modular RAG)
模块化 RAG 将 RAG 系统视为一个由多个可插拔、可替换、可配置的模块组成的灵活框架。这种范式允许根据具体需求定制和优化 RAG 流程,是当前 RAG 发展的主流趋势。
核心模块 (Core Modules):
- 搜索模块 (Search Module): 负责执行实际的检索操作,可以集成多种检索引擎(向量搜索、关键词搜索、图搜索)和数据库。
- 记忆模块 (Memory Module): 存储和利用历史交互信息(如对话历史、用户偏好、先前检索结果)来个性化检索和生成过程,或支持多轮对话。Self-Mem (Cheng, X. et al., 2023) 利用迭代的检索增强生成器构建记忆池。
- 融合模块 (Fusion Module): 当从多个来源或通过多种方法检索到信息时,融合模块负责将这些信息整合起来,例如对不同检索器的结果进行加权融合或选择最佳结果。RAG-Fusion (Rackauckas, 2024) 采用多查询策略并通过倒数排名融合(RRF)整合多路检索结果。
- 路由模块 (Routing Module): 根据查询的类型、意图或复杂性,将查询导向不同的处理路径、知识源或特定工具。例如,简单的事实查询可能直接由 LLM 回答,而复杂查询则需要经过多步检索和推理。
- 预测模块 (Predict Module): 在某些场景下,可以预测用户可能需要的下一步信息或操作,主动提供相关内容或建议。GenRead (Yu et al., 2023) 提出用 LLM 生成的上下文替代检索。
- 任务适配器 (Task Adapter Module): 针对特定的下游任务(如问答、摘要、对话、代码生成)调整 RAG 的行为、提示和输出格式。PROMPTAGATOR (Dai et al., 2023) 或 UPRISE (Cheng, D. et al., 2023) 为特定任务自动检索提示。
交互模式 (Interaction Patterns):
- 重写-检索-阅读 (Rewrite-Retrieve-Read): 先利用 LLM 重写用户查询(例如,使其更清晰、更具体,或分解为子查询),再进行检索,最后让 LLM 基于检索结果生成答案。
- 生成-阅读 (Generate-Read / Retrieve-then-Read with Generated Content): 先让 LLM 生成初步内容(如假设性答案、草稿、或与查询相关的关键词/概念),再将这些生成的内容用于检索相关信息,最后进行修正或完善。
- 迭代检索 (Iterative Retrieval): 多轮检索和生成,每一轮的输出可以作为下一轮检索的输入或引导,逐步逼近最终答案。这对于需要多步推理的复杂问题尤其有效。例如,第一轮检索可能提供初步线索,LLM 基于这些线索生成新的查询或细化方向,进行第二轮检索。ITER-RETGEN (Shao et al., 2023) 就是一个迭代检索和生成的例子。
- 自适应检索 (Adaptive Retrieval):
- Self-RAG (Asai et al., 2024): LLM 在生成过程中动态决定是否需要检索以及检索什么内容。它会生成检索令牌(如
[Retrieve])和批判令牌(如ISREL、ISSUP、ISUSE)来评估是否需要外部知识、检索段落是否相关、答案是否被证据支持以及输出是否有用。如果判断需要检索,它会生成检索查询,获取信息,然后继续生成。 - FLARE (Forward-Looking Active REtrieval augmented generation) (Jiang, Z. et al., 2023): 一种主动检索方法。LLM 在生成答案时,会临时生成一个短期的未来句子。如果这个未来句子中包含低概率的词元(表明模型对这部分内容不确定),系统就会触发一次检索,查询与这个未来句子相关的信息,然后用检索到的信息重新生成。
- SKR (Self-Knowledge Guided Retrieval Augmentation) (Wang, Y. et al., 2023): 利用 LLM 自身的知识判断是否需要检索。
- AdaptiveRAG (Jeong et al., 2024): 通过分类器判断查询复杂度,动态选择检索策略。
- Self-RAG (Asai et al., 2024): LLM 在生成过程中动态决定是否需要检索以及检索什么内容。它会生成检索令牌(如
- 递归/分层检索 (Recursive/Hierarchical Retrieval): 例如 RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) (Sarthi et al., 2024),它通过递归地聚类文本块并生成摘要来构建一个树状的索引结构。查询时,可以从树的不同层级进行检索,从而在不同粒度上获取信息。
模块化 RAG 的设计理念使得 RAG 系统更加灵活、强大和易于维护,能够适应更广泛和复杂的应用场景。
核心检索技术详解
检索是 RAG 系统中至关重要的一环,其目的是从海量数据中快速准确地找到与用户查询最相关的信息。现代 RAG 系统,特别是与 Azure AI Search 等企业级搜索服务结合时,会利用多种先进的检索技术。
1. 全文检索 (Full-Text Search) - BM25
全文检索是一种经典的基于词频的稀疏向量检索方法。BM25 (Best Matching 25) 及其变种是目前最常用和最有效的全文检索算法之一 (Robertson and Zaragoza, 2009)。它通过计算查询词在文档中的词频 (Term Frequency, TF) 和逆文档频率 (Inverse Document Frequency, IDF) 来评估文档与查询的相关性。
BM25 的评分公式通常如下:
\[ \begin{aligned} \text{score}(Q, D) = \sum_{q_i \in Q} \text{IDF}(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)} {f(q_i, D) + k_1 \cdot \left(1 - b + b \cdot \frac{|D|}{\text{avgdl}}\right)} \end{aligned} \]其中:
- \( Q = \{q_1, q_2, \ldots, q_m\} \) 是用户查询,包含 \( m \) 个查询词。
- \( D \) 是一个待评分的文档。
- \( \text{IDF}(q_i) \) 是查询词 \( q_i \) 的逆文档频率,衡量词语的稀有程度。计算方式通常为: $$ \text{IDF}(q_i) = \log\left(1 + \frac{N - n(q_i) + 0.5}{n(q_i) + 0.5}\right) $$ 其中 \( N \) 是文档总数,\( n(q_i) \) 是包含查询词 \( q_i \) 的文档数。
- \( f(q_i, D) \) 是查询词 \( q_i \) 在文档 \( D \) 中的词频。
- \( |D| \) 是文档 \( D \) 的长度(通常指词数)。
- \( \text{avgdl} \) 是数据集中所有文档的平均长度。
- \( k_1 \) 和 \( b \) 是可调参数:
- \( k_1 \) (通常取值在 1.2 到 2.0 之间) 控制词频饱和度,即词频对相关性得分的非线性影响。较高的 \( k_1 \) 值意味着词频对得分的贡献更大,直到达到一个饱和点。
- \( b \) (通常取值在 0.75 左右) 控制文档长度归一化的程度。当 \( b=1 \) 时,文档长度的影响被完全归一化;当 \( b=0 \) 时,不考虑文档长度。
BM25 的优点在于其简单、高效,并且在很多场景下能提供良好的基线性能。然而,它无法理解词语的语义相似性,例如无法识别同义词或近义词。
2. 向量搜索 (Vector Search) 与近似最近邻 (ANN)
向量搜索通过将文本(查询和文档块)转换为稠密的数值向量(嵌入向量, embeddings),然后在向量空间中查找与查询向量最相似的文档向量。这种方法能够捕捉文本的语义信息。
生成嵌入向量通常使用预训练的深度学习模型,如 BERT、Sentence-BERT、BGE、E5、OpenAI text-embedding-3-small / text-embedding-3-large 等。相似度计算常用余弦相似度(已在“RAG 基础知识”中定义)。
由于向量数据库可能包含数百万甚至数十亿个向量,进行精确的暴力搜索(称为 Flat 搜索或 K-Nearest Neighbors, KNN)计算成本非常高。因此,实际应用中广泛采用近似最近邻 (Approximate Nearest Neighbor, ANN) 算法,它们牺牲一定的精度来换取检索速度的大幅提升。常见的 ANN 算法(如 LSH, IVF)已在“RAG 基础知识”的索引部分提及,这里重点介绍 HNSW:
- 分层可导航小世界图 (Hierarchical Navigable Small World, HNSW): HNSW 是一种基于图的 ANN 算法,因其出色的性能(高召回率和高查询速度)而被广泛应用 (Malkov and Yashunin, 2020)。
- 构建过程: HNSW 构建一个多层图结构。最底层包含所有数据点。每一层都是下一层的一个子集,层数越高,节点越稀疏,连接的边也越长(跳跃性更大)。在每一层中,节点都与其“近邻”相连,形成一个可导航的小世界网络。新节点插入时,会从顶层开始贪婪地搜索其最近邻,并在每一层找到的最近邻基础上,在下一层继续搜索,直到到达底层。然后,新节点会与找到的最近邻建立连接。
- 搜索过程: 查询时,从顶层的入口点(entry point)开始,贪婪地向着查询向量方向在当前层图上移动,直到找到局部最优(即当前节点的所有邻居中没有比它更接近查询向量的)。然后,将这个局部最优点作为下一层的入口点,重复此过程,直到到达最底层。在最底层找到的若干最近邻即为最终的近似结果。
- HNSW 的关键参数包括
M(每个节点的最大出度)、efConstruction(构建图时动态候选列表的大小)和efSearch(搜索时动态候选列表的大小)。
3. 混合搜索 (Hybrid Search) 与 RRF
混合搜索结合了全文检索(如 BM25)和向量搜索的优点。全文检索擅长匹配关键词,而向量搜索擅长理解语义。通过融合两者的结果,可以获得更全面和相关的搜索结果。Azure AI Search 等现代搜索引擎提供了强大的混合搜索功能。
倒数排序融合 (Reciprocal Rank Fusion, RRF) 是一种常用的无参数结果融合算法,它根据文档在不同检索系统结果列表中的排名来计算最终得分 (Cormack et al., 2009)。 RRF 的评分公式为:
$$ \text{RRFScore}(D) = \sum_{r \in R_{systems}} \frac{1}{k_{rrf} + \text{rank}_r(D)} $$其中:
- \( D \) 是一个待评分的文档。
- \( R_{systems} \) 是参与融合的检索系统(例如,一个 BM25 检索器和一个向量检索器)的集合。
- \( \text{rank}_r(D) \) 是文档 \( D \) 在检索系统 \( r \) 返回结果列表中的排名(从1开始)。如果文档 \( D \) 未被系统 \( r \) 检索到,则其排名可以视为无穷大,或者该项不参与求和。
- \( k_{rrf} \) 是一个小常数(例如 60),用于平滑排名影响,减少排名靠前但仅被一个系统检索到的文档的权重过高问题。
RRF 的优点在于其简单性、无需训练参数,并且对不同检索系统的得分范围不敏感,只依赖于排名。
4. 重排序 (Reranking)
重排序是在初步检索(召回阶段)之后,对候选文档列表进行更精细的排序,以提高最终结果的质量。召回阶段通常使用计算效率较高的方法(如 BM25、ANN)快速筛选出大量潜在相关的文档,而重排序阶段则可以使用计算成本较高但更精确的模型来处理这个较小的候选集。
常见的重排序方法包括:
- 基于交叉编码器的重排序 (Cross-encoder Reranking): 交叉编码器(如基于 BERT 的模型)将查询和每个候选文档拼接起来作为输入,共同编码后输出一个相关性得分。这种方式能够捕捉查询和文档之间更细致的交互信息,因此排序效果通常优于双编码器(用于向量检索)。但由于需要对每个查询-文档对进行独立编码,计算成本较高,不适合用于大规模召回。
- 基于 LLM 的重排序: 可以利用大型语言模型强大的理解和推理能力来进行重排序。例如,可以设计提示让 LLM 评估每个候选文档与查询的相关性,或者比较多个候选文档的优劣。
重排序是提升 RAG 系统性能的关键步骤,尤其是在处理复杂查询或需要高度相关上下文的场景中。
图 RAG (GraphRAG)
传统的 RAG 方法主要依赖于文本块的独立检索,难以捕捉和利用文档集合中实体之间以及概念之间的复杂关系和全局上下文。GraphRAG (Edge et al., 2024; Peng et al., 2024; GitHub) 通过构建和利用知识图谱(Knowledge Graphs, KGs)来解决这一问题,从而支持更深层次的理解和全局性问题的回答。

Fig. 4. The GraphRAG pipeline using LLM-derived graph indexing. (Image source: Edge et al., 2024)
图 4 展示了微软 GraphRAG 基于 LLM 的图索引构建流程。其核心流程包括:
- 知识图谱构建 (Knowledge Graph Construction):
- 文本分块 (Text Chunking): 与标准 RAG 类似,首先将源文档分割成文本块。
- 实体与关系提取 (Entities & Relationships Extraction): 使用 LLM 从每个文本块中提取关键实体(如人物、组织、地点、概念等)及其属性,以及实体之间的关系。LLM 还会为这些实体和关系生成简短描述。
- 声明提取 (Claim Extraction): LLM 还可以被提示提取关于实体的关键事实性声明。
- 图谱生成 (Graph Generation): 将提取的实体作为图的节点,关系作为边,声明可以作为节点或边的属性。重复检测到的实体和关系可以进行合并,关系出现的频率可以作为边的权重。
- 图社区检测与摘要 (Graph Communities & Summaries):
- 社区检测 (Community Detection): 应用图社区检测算法(如 Leiden 算法 (Traag et al., 2019))将知识图谱划分为若干个紧密连接的实体社区。这个过程可以是分层的,即在每个社区内部递归地检测子社区。
- 社区摘要生成 (Community Summaries Generation): 使用 LLM 为每个社区(在不同层级上)生成摘要。叶子节点的社区摘要基于其内部实体、关系和声明的描述。更高层级社区的摘要则递归地整合其子社区的摘要和该层级新增的关联信息。这些社区摘要提供了对数据不同粒度下的全局性描述和洞察。
- 查询与答案生成 (Querying & Answering):
- 社区答案映射 (Map Community Answers): 当用户提出查询时,针对选定层级的每个社区摘要,LLM 会并行地生成一个与查询相关的局部答案,并给出一个该局部答案对回答原始问题的“帮助性”评分。
- 全局答案归约 (Reduce to Global Answer): 将所有局部答案根据其帮助性评分进行排序,然后迭代地将评分最高的局部答案添加到新的上下文中(直到达到 LLM 的上下文窗口限制),最后 LLM 基于这个整合的上下文生成最终的全局答案。
GraphRAG 的优势:
- 全局上下文理解: 通过社区检测和分层摘要,能够回答需要理解整个语料库的“全局性”或“探索性”问题,例如“数据集中的主要主题是什么?”或“不同概念之间是如何关联的?”。这是传统 RAG 难以实现的。
- 结构化知识表示: 将非结构化文本转化为实体-关系图谱,支持更丰富的语义查询和知识发现。
- 可解释性增强: 社区摘要和实体关系为答案提供了可追溯的结构化依据。
- 多粒度检索: 支持从不同层级的社区摘要中检索信息,适应不同粒度的查询需求。
GraphRAG 的挑战:
- 知识图谱的构建和维护成本较高,且质量难以保证。
- 如何有效地将图结构信息与 LLM 的输入/输出进行对齐和融合。
- 图检索算法的效率和可扩展性。
其他 GraphRAG 方法
除了微软提出的 GraphRAG 流程,还有其他利用图结构增强 RAG 的方法:
- G-Retriever (He et al., 2024): 一种用于文本图理解和问答的检索增强生成方法。
- Agent-G (Lee et al., 2024): 一个基于代理的图检索增强生成框架,动态地分配检索任务给专门的代理,这些代理可以分别从图知识库和非结构化文档中检索信息,并通过反馈循环进行迭代优化。
- GeAR (Graph-Enhanced Agent for Retrieval-Augmented Generation) (Shen et al., 2024): GeAR 通过图扩展技术(Graph Expansion)来增强传统检索器(如 BM25)的能力。它将图结构数据整合到检索过程中,使得系统能够捕捉实体间的复杂关系和依赖,从而更好地处理多跳查询。
这些方法都强调了图结构在 RAG 中的重要性,尤其是在需要复杂推理和多源信息整合的场景下。
Agentic RAG
Agentic RAG (Singh et al., 2025) 是一种更高级的 RAG 范式,它将自主代理(AI Agents)集成到 RAG 流程中。这些代理能够进行动态决策、规划、使用工具并进行协作,从而实现更灵活、更智能的检索和生成过程。

Fig. 5. Overview of AI Agent components. (Image source: Singh et al., 2025)
图 5 展示了 AI Agent 的核心组件及其在 Agentic RAG 中的作用。
代理 RAG 的核心在于赋予 RAG 系统更强的自主性和适应性,使其能够处理更复杂、动态和多步骤的任务。其关键的代理模式包括:
- 反思 (Reflection): 代理能够评估和迭代改进其自身的输出或中间结果。通过自我批评和反馈机制,代理可以识别错误、不一致之处,并进行修正。Self-Refine (Madaan et al., 2023), Reflexion (Shinn et al., 2023), 和 CRITIC (Gou et al., 2024) 是相关研究。
- 规划 (Planning): 代理能够将复杂任务分解为更小、可管理的子任务,并规划执行顺序。这对于需要多跳推理或动态调整策略的场景至关重要。
- 工具使用 (Tool Use): 代理可以调用外部工具、API 或计算资源来扩展其能力,例如执行代码、访问数据库、进行网络搜索等。Toolformer (Schick et al., 2023) 和 GraphToolformer (Zhang, 2023) 是让 LLM 学会使用工具的例子。
- 多代理协作 (Multi-Agent Collaboration): 多个具有不同专长或角色的代理可以协同工作,共同完成一个复杂任务。它们可以通信、共享中间结果,实现任务的并行处理和专业化分工。AutoGen (Wu, Q. et al., 2023) 和 CrewAI 是支持多代理协作的框架。
基于这些模式,Agentic RAG 可以从架构形态和控制机制两个维度理解。架构形态决定多个代理如何分工,控制机制则决定系统如何纠错、何时检索以及如何学习检索策略。
架构形态
单代理 RAG (Single-Agent Agentic RAG: Router)
由一个中心化的代理负责管理整个 RAG 流程,包括接收用户查询、分析查询意图、选择合适的知识源(如结构化数据库、向量数据库、网络搜索)、执行检索、整合信息并驱动 LLM 生成答案。这种架构相对简单,适用于任务明确或工具集有限的场景。
多代理 RAG (Multi-Agent Agentic RAG)
将 RAG 流程中的不同职责分配给多个专门的代理。例如,可以有专门负责查询理解的代理、负责从不同类型数据源(SQL 数据库、文档库、API)检索信息的检索代理、负责信息融合的代理以及负责最终答案生成的代理。这些代理并行工作并通过协调器进行协作。这种架构具有更好的模块化和可扩展性。
分层代理 RAG (Hierarchical Agentic RAG)
代理被组织成一个层次结构。高层代理负责战略规划和任务分解,并将子任务分配给低层代理执行。低层代理专注于特定的检索或处理任务,并将结果汇报给高层代理进行整合与综合。这种架构适合处理非常复杂、需要多层次决策的查询。
相关机制与训练范式
纠正性 RAG (Corrective RAG / CRAG)
CRAG (Yan et al., 2024) 引入了对检索结果进行自我纠正的机制。它包含一个评估器来判断检索到的文档的相关性。如果文档相关性高,则直接用于生成;如果相关性低或不确定,系统会触发额外的操作,如从其他来源(如网络)进行补充检索,或者对检索到的文档进行分解和筛选,以提高最终生成答案的鲁棒性和准确性。
自适应 RAG (Adaptive RAG)
自适应 RAG (Jeong et al., 2024) 根据查询复杂性动态选择检索策略(无检索/单次检索/多轮迭代),详见模块化 RAG 中的自适应检索部分。
基于强化学习的 Agentic RAG
2025 年,基于强化学习训练 LLM 自主决定何时及如何检索成为 Agentic RAG 的重要方向:
Search-R1 (Jin et al., 2025): 使用 RL 训练 LLM 在逐步推理过程中自主生成搜索查询并进行实时检索。引入 retrieved token masking 实现稳定的 RL 训练;在论文报告的七个 QA 数据集和相同检索设置下,Qwen2.5-7B 相比若干 RAG baseline 有显著提升。
R1-Searcher (Song et al., 2025): 纯 RL 方法(无需过程奖励或蒸馏),教会 LLM 在推理过程中自主调用搜索。其优势应限定在论文实验的 QA 基准、检索环境和评测指标内,不应理解为通用模型能力排序。
Search-o1 (Li et al., 2025): 将 agentic RAG 集成到大型推理模型(如 o1)的推理过程中。包含 Reason-in-Documents 模块,在注入前分析检索文档以减少噪声。在科学、数学、编程和开放域 QA 上表现强劲。
多模态 RAG (Multimodal RAG)
随着信息的多样化,仅仅处理文本数据已不能满足许多应用场景的需求。多模态 RAG (Multimodal RAG) (Abootorabi et al., 2025; Zhao et al., 2023) 将 RAG 的能力扩展到多种数据模态,如文本、图像、音频、视频等。它旨在通过从包含多种类型数据的外部知识库中检索和融合信息,来增强多模态大型语言模型 (MLLMs) 的生成能力。

Fig. 6. Overview of the Multimodal Retrieval-Augmented Generation (RAG) pipeline. (Image source: Abootorabi et al., 2025)
图 6 展示了多模态 RAG 的整体流程,包括多模态数据的处理、检索和生成。
任务定义
给定一个多模态查询 \( q \) 和一个包含多种模态文档 \( D = \{d_1, d_2, \ldots, d_n\} \) 的语料库,多模态 RAG 的目标是检索相关的多模态证据并生成响应 \( r \)(通常为文本答案,也可能包含多模态内容)。 每个文档 \( d_i \) 具有其自身的模态 \( M_{d_i} \)。首先,使用特定于模态的编码器 \( \text{Enc}_{M_{d_i}}(\cdot) \) 将每个文档 \( d_i \) 编码为一个向量表示 \( z_i \):
$$ z_i = \text{Enc}_{M_{d_i}}(d_i) $$这些编码器通常旨在将不同模态的信息映射到一个共享的语义空间,以便进行跨模态对齐和比较。 然后,检索模型 \( R \) 根据查询 \( q \)(其编码表示为 \( e_q \))与每个编码后的文档 \( z_i \) 之间的相关性评分 \( s(e_q, z_i) \) 来选择最相关的文档子集 \( X \):
$$ X = \{d_i \mid s(e_q, z_i) \geq \tau_{M_{d_i}}\} $$其中 \( \tau_{M_{d_i}} \) 是针对模态 \( M_{d_i} \) 的相关性阈值。 最后,生成模型 \( G_{model} \) 利用原始查询 \( q \) 和检索到的多模态上下文 \( X \) 来生成最终的多模态响应 \( r \):
$$ r = G_{model}(q, X) $$关键技术与创新
多模态 RAG 的实现涉及以下几个关键环节的技术创新(Abootorabi et al., 2025):
多模态数据处理与索引 (Multimodal Data Processing and Indexing)
- 对不同模态的数据进行预处理和特征提取。例如,图像可用视觉编码器(如 ViT、CLIP Image Encoder (Radford et al., 2021))提取特征向量;音频可先用 ASR 转文本,或利用音频编码器(如 CLAP (Wu, Y. et al., 2023))提取声学向量。
- 将不同模态的特征向量存储在多模态向量数据库中,或为每种模态维护独立索引。MegaPairs (Zhou et al., 2024) 是一个大规模多模态配对数据集,可用于训练通用检索器。
多模态检索策略 (Multimodal Retrieval Strategy)
高效搜索与相似性检索: 依赖于把不同模态输入映射到统一嵌入空间的模型,如基于 CLIP (Radford et al., 2021) 或 BLIP (Li et al., 2022)。利用 MIPS(通过 ScaNN、FAISS 等库实现)进行高效检索。
模态中心检索 (Modality-Centric Retrieval):
- 文本中心: 基于传统文本检索方法,使用 BM25、DPR、Contriever (Izacard et al., 2022) 等。
- 视觉中心: 直接基于图像向量检索,如 EchoSight、ImgRet;CIR (Composed Image Retrieval) 模型支持多图组合查询。
- 视频中心: 融合时序动态信息,例如 iRAG (Arefeen et al., 2024) 的增量检索、Video-RAG (Luo et al., 2024) 借助 OCR/ASR 辅助文本。
- 文档检索与布局理解: 处理含文本、图像、表格、布局信息的整页文档,如 ColPali (Faysse et al., 2024)、DocLLM (Wang et al., 2024)。
重排序与选择策略:
- 优化样本选择: 采用多步检索,结合有监督 / 无监督的候选筛选。
- 相关性评分评估: 使用 CLIP/BLIP 相似度、跨编码器或 MLLM reranker,以及 Recall@K、mAP、NDCG 等检索指标进行重排序与评估;SSIM、NCC 等像素级指标只适用于特定图像布局或视觉匹配场景。
- 过滤机制: 通过硬负例挖掘、一致性过滤等方法去除不相关结果。
多模态融合机制 (Multimodal Fusion Mechanisms)
- 分数融合与对齐 (Score Fusion and Alignment): 将不同模态的检索得分或特征进行融合。例如,将文本、表格、图像转换为统一的文本格式后进行评分,或将图像和查询嵌入到共享的 CLIP 空间中。REVEAL (Hu et al., 2023) 将检索分数注入注意力层。
- 基于注意力的机制 (Attention-Based Mechanisms): 使用交叉注意力等机制动态加权不同模态间的交互,以支持特定任务的推理。例如,RAMM (Yuan et al., 2023) 使用双流共同注意力 Transformer。
- 统一框架与投影 (Unified Frameworks and Projections): 将多模态输入整合为一致的表示。例如,M3DocRAG (Cho et al., 2024) 将多页文档展平为单个嵌入张量;SAM-RAG (Zhai, 2024) 通过为图像生成标题,将多模态输入转换为单模态文本。
多模态增强技术 (Multimodal Augmentation Techniques)
上下文丰富 (Context Enrichment): 通过添加额外的上下文元素(文本块、图像标记、结构化数据)来增强检索知识的相关性。
自适应与迭代检索 (Adaptive and Iterative Retrieval):
- 自适应检索: 根据查询复杂度动态调整检索策略。SKURG (Yang et al., 2022) 根据查询复杂度决定检索跳数;OmniSearch (Li, Y. et al., 2024) 使用自适应检索代理分解复杂问题。
- 迭代检索: 通过多轮检索并结合先前迭代的反馈来优化结果。
多模态生成技术 (Multimodal Generation Techniques)
- 上下文学习 (In-Context Learning, ICL): 利用检索到的多模态内容作为少样本示例,无需重新训练即可增强 MLLM (如 GPT-4V (OpenAI, 2023), LLaVA (Liu, H. et al., 2023), Gemini (Gemini Team, 2024)) 的推理能力。
- 推理 (Reasoning): 使用结构化推理技术(如 Chain-of-Thought)将复杂推理分解为顺序步骤。RAGAR (Khaliq et al., 2024) 引入 Chain of RAG 和 Tree of RAG。
- 指令调优 (Instruction Tuning): 针对特定应用对生成组件进行微调或指令调优。RA-BLIP (Ding et al., 2024) 利用 InstructBLIP 的 QFormer 架构。
- 来源归属与证据透明性 (Source Attribution and Evidence Transparency): 确保生成的内容能追溯到其原始来源。VISA (Ma et al., 2024) 生成带有视觉来源归属的答案。
训练策略与损失函数 (Training Strategies and Loss Functions):
- 对齐 (Alignment): 主要使用对比学习(Contrastive Learning)来提高表示质量,常用损失函数为 InfoNCE loss: $$ \mathcal{L}_{\text{InfoNCE}} = -\log \frac{\exp(\text{sim}(z_i, z_j) / \tau)}{\sum_{k=1}^{K} \exp(\text{sim}(z_i, z_k) / \tau)} $$ 其中 \( z_i, z_j \) 是正样本对的嵌入,分母中 \( z_k \) 遍历所有候选样本(包含正例 \( z_j \) 和 \( K-1 \) 个负样本),\( \tau \) 是温度参数。
- 生成 (Generation):
- 文本生成:通常使用交叉熵损失 (Cross-Entropy Loss)。
- 图像/视频生成:常用生成对抗网络 (GANs) 或扩散模型 (Diffusion Models) 的标准训练损失。
- 鲁棒性与噪声管理 (Robustness and Noise Management): 通过在训练中注入不相关结果、使用渐进式知识蒸馏、噪声注入训练(如添加硬负例、高斯噪声)等方法来提高模型对噪声输入的鲁棒性。
多模态 RAG 通过整合来自不同来源和类型的知识,极大地丰富了 LLM 的上下文理解和生成能力,为构建更智能、更全面的 AI 系统奠定了基础。例如,在 SharePoint 文档库中,可能包含 PPT、Word 文档、图片等,多模态 RAG 可以帮助用户基于这些混合内容进行问答。
多模态 RAG 前沿进展
ViDoRAG (Wang, Q. et al., 2025): 面向视觉文档的多智能体 RAG 系统,使用基于 GMM 的混合检索结合文本和视觉特征。采用迭代式智能体工作流(探索、总结、反思),比现有方法提升超过 10%。
MegaRAG (Hsiao et al., 2025): 基于多模态知识图谱的 RAG,支持跨模态推理。将视觉线索整合到知识图谱的构建、检索和答案生成中,同时支持全局和细粒度问答。
RAG 前沿进展概览
近年来,RAG 领域涌现了多项突破性进展,进一步推动了范式演进:
CoRAG (Chain-of-Retrieval Augmented Generation) (Wang, L. et al., 2025, Microsoft): 训练“o1-like RAG 模型”,通过拒绝采样生成中间检索链,实现逐步检索与推理。在论文报告的多跳问答设置下提升 10+ EM 分数,并展示了 RAG 的测试时计算扩展能力。
Contextual Retrieval (Anthropic, 2024): Anthropic 提出的预处理技术,使用 Claude 为每个文本块添加 50-100 token 的上下文说明后再进行嵌入和索引。结合 Contextual Embeddings + Contextual BM25 + Reranking,实现检索失败率降低 67%。利用 prompt caching 将成本降至每百万文档 token 约 1.02 美元。
PRAG (Parametric Retrieval Augmented Generation) (Su et al., 2025): 提出将外部知识直接整合到 FFN 参数中的新范式,而非附加到输入上下文。消除了上下文长度开销,实现更深层的知识整合,并可与传统 in-context RAG 结合进一步提升效果。
HippoRAG 2 (Gutierrez et al., 2025): 将 RAG 推向类人长期记忆系统,使用增强的 Personalized PageRank 实现更深层的段落整合。在论文报告的关联记忆任务中,比相关 SOTA 嵌入模型提升 7%,同时在事实和语义理解任务上表现优异。
RAG vs. Long-Context (Li, Z. et al., 2024, Google, EMNLP 2024): 对 RAG 与长上下文 LLM(包括 Gemini-1.5 和 GPT-4)进行了全面基准测试。提出 Self-Route 方法,根据模型自我反思将查询路由到 RAG 或长上下文处理。发现长上下文在某些任务上表现更优,但 RAG 在成本效率和特定检索密集型任务上仍具显著优势,两者各有适用场景。
RAG 系统的评估
评估 RAG 系统的性能是一个多维度的问题,需要同时考虑检索质量和生成质量。
1. Ragas 框架核心指标
Ragas (Retrieval Augmented Generation Assessment) (Es et al., 2023, GitHub) 是一个专注于 RAG 系统自动化、主要依赖 LLM 进行无参考或有参考评估的框架。它提出了一系列指标,用于从不同维度评估 RAG 流水线。
Ragas 关注以下核心质量维度:
忠实度 (Faithfulness):
- 定义: 衡量生成的答案 \( A \) 是否完全基于给定的上下文 \( C \) 得出,即答案中的声明是否都能从上下文中推断出来。这个指标对于避免幻觉至关重要。
- 计算方法 (Ragas):
- 使用 LLM 从生成的答案 \( A \) 中提取一组声明(statements)\( S = \{s_1, s_2, \ldots, s_m\} \)。
- 对于每个声明 \( s_i \in S \),再次使用 LLM 验证该声明是否可以从上下文 \( C \) 中推断出来。得到一个验证为真的声明集合 \( V \)。
- 忠实度得分 \( F_{faithfulness} \) 计算为: $$ F_{faithfulness} = \frac{|V|}{|S|} $$ 其中 \( |V| \) 是被验证为真实的声明数量,\( |S| \) 是从答案中提取的声明总数。得分范围为 \( [0, 1] \),越高越好。
答案相关性 (Answer Relevance):
- 定义: 衡量生成的答案 \( A \) 与原始问题 \( Q \) 的相关程度。它惩罚不完整或包含冗余信息的答案。
- 计算方法 (Ragas):
- 给定生成的答案 \( A \),使用 LLM 生成 \( n_{q'} \) 个可能的反向问题 \( Q' = \{q'_1, q'_2, \ldots, q'_{n_{q'}}\} \),这些问题应该可以由答案 \( A \) 来回答。
- 计算每个生成的反向问题 \( q'_j \) 与原始问题 \( Q \) 之间的嵌入相似度 \( \text{sim}(Q, q'_j) \)(例如使用 OpenAI text-embedding-3-small 计算余弦相似度)。
- 答案相关性得分 \( \text{AR} \) 计算为这些相似度的平均值: $$ \text{AR} = \frac{1}{n_{q'}} \sum_{j=1}^{n_{q'}} \text{sim}(Q, q'_j) $$ 得分范围为 \( [0, 1] \),越高越好。
上下文精确率 (Context Precision):
- 定义: 衡量检索到的上下文块列表中,相关块是否排在靠前的位置。它是一个基于排序的指标,奖励将相关上下文排在前面的检索器。
- 计算方法 (Ragas 中的 Context Precision):
- 给定问题 \( Q \) 和检索到的 \( K \) 个上下文块的有序列表 \( C = [c_1, c_2, \ldots, c_K] \),使用 LLM 判断每个块 \( c_k \) 是否对回答问题有用,得到二值标签 \( v_k \in \{0, 1\} \)。
- 上下文精确率计算为各位置 precision@k 的加权平均: $$ \text{Context Precision} = \frac{\sum_{k=1}^{K} (\text{Precision@}k \times v_k)}{\text{总相关块数}} $$ 其中 \( \text{Precision@}k = \frac{\text{前 } k \text{ 个块中相关块数}}{k} \)。该指标惩罚相关块排在列表后面的情况。得分范围为 \( [0, 1] \),越高越好。
上下文召回率 (Context Recall): (需要真实答案 Ground Truth)
- 定义: 衡量检索到的上下文 \( C \) 是否包含了回答问题 \( Q \) 所需的所有真实答案 \( GT \) 中的信息。
- 计算方法 (Ragas): 对于真实答案 \( GT \) 中的每个句子,判断其是否可以从检索到的上下文 \( C \) 中归因得到。上下文召回率 \( \text{CR}_{recall} \) 是可归因的真实答案句子数 \( |S_{GT\_attributable}| \) 与真实答案总句数 \( |S_{GT}| \) 的比率。 $$ \text{CR}_{recall} = \frac{|S_{GT\_attributable}|}{|S_{GT}|} $$
答案语义相似度 (Answer Semantic Similarity): (需要真实答案 Ground Truth)
- 定义: 衡量生成的答案与标准答案之间的语义相似度。
- 计算方法 (Ragas): 通常使用嵌入模型计算两个答案向量的余弦相似度。 $$ \text{Answer Semantic Similarity} = \text{sim}(E(A_{\text{generated}}), E(A_{\text{GT}})) $$
答案正确性 (Answer Correctness): (需要真实答案 Ground Truth)
- 定义: 衡量生成的答案在事实层面上的正确性,与标准答案的一致性。
- 计算方法 (Ragas): 结合事实相似性和语义相似性进行评估,判断生成答案与标准答案是否表达相同的事实。
2. 其他检索质量评估指标
- 命中率 (Hit Rate): 衡量检索到的文档中是否至少包含一个正确答案或相关信息。
- 平均倒数排名 (Mean Reciprocal Rank, MRR): 评估检索结果中第一个相关文档的排名。对于一组查询 \( Q_{set} \),MRR 计算如下: $$ \text{MRR} = \frac{1}{|Q_{set}|} \sum_{i=1}^{|Q_{set}|} \frac{1}{\text{rank}_i} $$ 其中 \( \text{rank}_i \) 是第 \( i \) 个查询的第一个相关文档的排名。
- 归一化折扣累积增益 (Normalized Discounted Cumulative Gain, NDCG@k): 考虑检索结果的排序和相关性等级。 $$ \text{DCG}@k = \sum_{i=1}^{k} \frac{2^{\text{rel}_i} - 1}{\log_2(i+1)} \quad ; \quad \text{NDCG}@k = \frac{\text{DCG}@k}{\text{IDCG}@k} $$ 其中 \( \text{rel}_i \) 是排名第 \( i \) 位的文档的相关性得分,\( \text{IDCG}@k \) 是理想排序下的 DCG@k 值。
3. 其他生成质量评估指标
- BLEU (Bilingual Evaluation Understudy) (Papineni et al., 2002): 基于 N-gram 精确率。 $$ \text{BLEU} = \text{BP} \cdot \exp\left(\sum_{n=1}^{N} w_n \log p_n\right) $$
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) (Lin, 2004): 基于 N-gram 召回率。 \[ \begin{aligned} \text{ROUGE-N} = \frac{ \sum_{S \in \{\text{RefSummaries}\}} \sum_{\text{gram}_n \in S} \text{Count}_{\text{match}}(\text{gram}_n) }{ \sum_{S \in \{\text{RefSummaries}\}} \sum_{\text{gram}_n \in S} \text{Count}(\text{gram}_n) } \end{aligned} \]
- METEOR (Metric for Evaluation of Translation with Explicit ORdering) (Banerjee and Lavie, 2005): 基于对齐的词级别匹配。
- BERTScore (Zhang et al., 2019): 计算嵌入之间的余弦相似度。
- 困惑度 (Perplexity, PPL): 衡量语言模型对其生成文本的自信程度。 \[ \begin{aligned} \text{PPL}(W) &= P(w_1 w_2 \dots w_N)^{-\frac{1}{N}} \\ &= \sqrt[N]{\frac{1}{P(w_1 w_2 \dots w_N)}} \end{aligned} \]
4. 端到端评估与基准
- Ragas (Retrieval Augmented Generation Assessment) (Es et al., 2023):如上所述,提供了一套自动化的评估指标。
- ARES (Automated RAG Evaluation System) (Saad-Falcon et al., 2023):使用 LLM 生成的合成数据进行评估。
- TruLens (TruLens Docs, 2024):关注上下文相关性、无害性/忠实度和答案相关性。
- RGB (RAG Benchmark) (Chen, J. et al., 2024):评估噪声鲁棒性、负例拒绝、信息整合和反事实鲁棒性。
- RECALL (Robustness Evaluation of Counterfactual Knowledge in RAG for LLMs) (Liu, X. et al., 2023):专注于反事实知识的鲁棒性。
- CRUD-RAG (Lyu et al., 2024):全面的中文 RAG 基准。
- BEIR (Benchmarking IR) (Thakur et al., 2021):通用信息检索基准。
- KILT (Knowledge Intensive Language Tasks) (Petroni et al., 2020):知识密集型任务基准。
- MTEB (Massive Text Embedding Benchmark) (Muennighoff et al., 2022):文本嵌入模型基准。
Ragas 等工具降低了人工评估的成本,使开发者可以更快迭代和优化 RAG 系统;但不同指标对 reference、ground truth 或 LLM-as-judge 的依赖不同,不能简单等同于完全无标注评估。
5. RAG 安全性与鲁棒性评估
SafeRAG (Liang et al., 2025): RAG 安全性基准,定义了四类攻击(银噪声、上下文间冲突、软广告、白色 DoS)。研究表明,即使是最明显的攻击也能轻易绕过现有的检索器、过滤器或高级 LLM。
ClashEval (Wu, K. et al., 2024): 包含 1200+ 问题的基准,通过校准扰动研究 RAG 中的知识冲突。发现 LLM 在超过 60% 的情况下会用错误的检索内容覆盖正确的内部先验知识。将 token 级不确定性与检索依赖性关联。
RAG 的应用场景
RAG 技术因其能够结合外部知识源的优势,在多种 NLP 应用中展现出巨大潜力:
- 开放域问答 (Open-Domain Question Answering): 如 DrQA (Chen et al., 2017)。
- 领域特定问答 (Domain-Specific QA): 医疗 (Zhu et al., 2024 - REALM for EHRs)、法律 (Cui et al., 2023 - ChatLaw)、金融 (Zhang et al., 2024 - AlphaFin)。
- 对话系统/聊天机器人 (Conversational AI/Chatbots): 如 BlenderBot 3 (Shuster et al., 2022)。
- 内容生成 (Content Generation): 生成报告、摘要等。
- 代码生成与辅助 (Code Generation and Assistance): 如 DocPrompting (Zhou et al., 2022)。
- 推荐系统 (Recommender Systems): 如 CoRAL (Wu, J. et al., 2024)。
- AI 智能体 (AI Agents): 作为 Agent 获取外部知识的核心能力。
- 多模态应用 (Multimodal Applications): 视觉问答、图像/视频字幕生成、文本到图像/视频生成。
- 科学研究 (AI for Science): 分子发现 (Li et al., 2023 - MolReGPT)、蛋白质研究。
结论
检索增强生成(RAG)不是单一模型技巧,而是一套围绕“知识如何进入上下文”的系统工程。落地时可以把重点放在以下几点:
- 检索质量决定上限。 分块、嵌入、BM25/向量混合检索、RRF 和重排序共同决定了 LLM 能看到什么证据;生成模型再强,也很难稳定弥补低召回、低相关或冲突的上下文。
- RAG、长上下文和微调各有边界。 RAG 更适合动态知识、私有知识和需要溯源的场景;长上下文适合少量长文档的整体理解;微调更适合学习格式、风格和任务行为。实际系统常常需要组合使用。
- GraphRAG、Agentic RAG 和多模态 RAG 扩展了问题空间。 图结构有助于全局主题和实体关系推理,Agentic RAG 适合多步骤工具调用,多模态 RAG 则让表格、图片、视频和版面信息进入检索与生成链路。
- 评估必须覆盖端到端风险。 除了 Recall@K、NDCG、faithfulness、answer relevance 等离线指标,还需要关注引用错配、上下文冲突、提示注入、语料污染、延迟和在线用户任务成功率。
未来的 RAG 系统会继续向更强的检索规划、更可靠的证据归因、更低成本的上下文压缩以及更细粒度的安全评估发展。对生产系统而言,最实用的原则仍然是:先保证知识源质量和可观测性,再逐步引入更复杂的图、代理和多模态能力。
参考文献
[1] Kandpal, Nikhil, et al. “Large language models struggle to learn long-tail knowledge.” ICML 2023.
[2] Liu, Nelson F., et al. “Lost in the middle: How language models use long contexts.” TACL 2024.
[3] OpenAI. “GPT-4V(ision) System Card.” OpenAI System Card (2023).
[4] Johnson, Jeff, et al. “Billion-scale similarity search with GPUs.” IEEE TBD 2019.
[5] Malkov, Yu A., and D. A. Yashunin. “Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs.” IEEE TPAMI 2020.
[6] Borgeaud, Sebastian, et al. “Improving language models by retrieving from trillions of tokens.” ICML 2022.
[7] Izacard, Gautier, et al. “Unsupervised dense information retrieval with contrastive learning.” TMLR 2022.
[8] Gao, Luyu, et al. “Precise zero-shot dense retrieval without relevance labels.” ACL 2023.
[9] Ma, Xinbei, et al. “Query rewriting for retrieval-augmented large language models.” EMNLP 2023.
[10] Jagerman, Rolf, et al. “Query expansion by prompting large language models.” arXiv preprint (2023).
[11] Jiang, Huiqiang, et al. “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models.” EMNLP 2023.
[12] Xu, Fangyuan, et al. “RECOMP: Improving retrieval-augmented LMs with compression and selective augmentation.” ICLR 2024.
[13] Chen, Tong, et al. “Dense X Retrieval: What retrieval granularity should we use?” arXiv preprint (2023).
[14] Cheng, Daixuan, et al. “UPRISE: Universal prompt retrieval for improving zero-shot evaluation.” EMNLP 2023.
[15] Cheng, Xin, et al. “Lift yourself up: Retrieval-augmented text generation with self-memory.” NeurIPS 2023.
[16] Rackauckas, Zackary. “RAG-Fusion: A new take on retrieval-augmented generation.” International Journal on Natural Language Computing (2024).
[17] Yu, Wenhao, et al. “Generate rather than retrieve: Large language models are strong context generators.” ICLR 2023.
[18] Dai, Zhuyun, et al. “Promptagator: Few-shot dense retrieval from 8 examples.” ICLR 2023.
[19] Asai, Akari, et al. “Self-RAG: Learning to retrieve, generate, and critique through self-reflection.” ICLR 2024.
[20] Jiang, Zhengbao, et al. “Active retrieval augmented generation.” EMNLP 2023.
[21] Wang, Yile, et al. “Self-knowledge guided retrieval augmentation for large language models.” NeurIPS 2023.
[22] Jeong, Soyeong, et al. “Adaptive-RAG: Learning to adapt retrieval-augmented large language models through question complexity.” NAACL 2024.
[23] Sarthi, Parth, et al. “RAPTOR: Recursive abstractive processing for tree-organized retrieval.” ICLR 2024.
[24] Shao, Zhihong, et al. “Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy.” EMNLP 2023.
[25] Wang, Liang, et al. “CoRAG: Chain-of-Retrieval Augmented Generation.” arXiv preprint (2025).
[26] Anthropic. “Contextual Retrieval.” Anthropic Engineering (2024).
[27] Su, Weihang, et al. “Parametric Retrieval Augmented Generation.” arXiv preprint (2025).
[28] Gutierrez, Bernal Jimenez, et al. “HippoRAG 2: From RAG to Memory.” arXiv preprint (2025).
[29] Li, Zhuowan, et al. “Retrieval augmented generation or long-context LLMs? A comprehensive study and hybrid approach.” EMNLP 2024.
[30] Robertson, Stephen, and Hugo Zaragoza. “The probabilistic relevance framework: BM25 and beyond.” Foundations and Trends in Information Retrieval 3.4 (2009).
[31] Cormack, Gordon V., Charles LA Clarke, and Stefan Buettcher. “Reciprocal rank fusion outperforms condorcet and individual rank learning methods.” SIGIR 2009.
[32] Edge, Darren, et al. “From local to global: A graph RAG approach to query-focused summarization.” arXiv preprint (2024).
[33] Traag, V. A., L. Waltman, and N. J. van Eck. “From Louvain to Leiden: Guaranteeing well-connected communities.” Scientific Reports 9 (2019).
[34] Hu, Ziniu, et al. “REVEAL: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory.” CVPR 2023.
[35] He, Xiaoxin, et al. “G-Retriever: Retrieval-augmented generation for textual graph understanding and question answering.” NeurIPS 2024.
[36] Peng, Hao, et al. “Graph retrieval-augmented generation: A survey.” arXiv preprint (2024).
[37] Singh, Aditi, et al. “Agentic retrieval-augmented generation: A survey on agentic RAG.” arXiv preprint (2025).
[38] Madaan, Aman, et al. “Self-Refine: Iterative refinement with self-feedback.” NeurIPS 2023.
[39] Shinn, Noah, et al. “Reflexion: Language agents with verbal reinforcement learning.” NeurIPS 2023.
[40] Gou, Zhibin, et al. “CRITIC: Large language models can self-correct with tool-interactive critiquing.” ICLR 2024.
[41] Schick, Timo, et al. “Toolformer: Language models can teach themselves to use tools.” NeurIPS 2023.
[42] Zhang, Jiawei. “Graph-ToolFormer: To empower LLMs with graph reasoning ability via prompt augmented by ChatGPT.” arXiv preprint (2023).
[43] Wu, Qingyun, et al. “AutoGen: Enabling next-gen LLM applications via multi-agent conversation.” arXiv preprint (2023).
[44] Yan, Shi-Qi, et al. “Corrective retrieval augmented generation.” arXiv preprint arXiv:2401.15884 (2024).
[45] Jin, Bowen, et al. “Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning.” arXiv preprint (2025).
[46] Song, Huatong, et al. “R1-Searcher: Incentivizing the search capability in LLMs via reinforcement learning.” arXiv preprint (2025).
[47] Li, Xiaoxi, et al. “Search-o1: Agentic search-enhanced large reasoning models.” arXiv preprint (2025).
[48] Abootorabi, Mohammad Mahdi, et al. “A survey on multimodal retrieval augmented generation.” arXiv preprint (2025).
[49] Zhao, Penghao, et al. “Retrieving multimodal information for augmented generation: A survey.” EMNLP 2023.
[50] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” ICML 2021.
[51] Liu, Haotian, et al. “Visual instruction tuning.” NeurIPS 2023.
[52] Faysse, Manuel, et al. “ColPali: Efficient document retrieval with vision language models.” arXiv preprint (2024).
[53] Chen, Jianlv, et al. “BGE M3-Embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.” arXiv preprint (2024).
[54] Cho, Jaemin, et al. “M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding.” arXiv preprint (2024).
[55] Li, Junnan, et al. “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation.” ICML 2022.
[56] Lin, Xi Victoria, et al. “RA-DIT: Retrieval-augmented dual instruction tuning.” ICLR 2024.
[57] Ding, Yujian, et al. “RA-BLIP: Multimodal Adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training.” arXiv preprint (2024).
[58] Luo, Yongdong, et al. “Video-RAG: Visually-aligned Retrieval-Augmented Long Video Comprehension.” arXiv preprint (2024).
[59] Wang, Qiuchen, et al. “ViDoRAG: Visual document retrieval-augmented generation via dynamic iterative reasoning agents.” arXiv preprint (2025).
[60] Hsiao, Chi-Hsiang, et al. “MegaRAG: Multimodal knowledge graph-based RAG.” ACL 2026.
[61] Es, Shahul, et al. “RAGAS: Automated evaluation of retrieval augmented generation.” arXiv preprint (2023).
[62] Papineni, Kishore, et al. “BLEU: A method for automatic evaluation of machine translation.” ACL 2002.
[63] Banerjee, Satanjeev, and Alon Lavie. “METEOR: An automatic metric for MT evaluation with improved correlation with human judgments.” ACL Workshop 2005.
[64] Lin, Chin-Yew. “ROUGE: A package for automatic evaluation of summaries.” ACL Workshop 2004.
[65] Zhang, Tianyi, et al. “BERTScore: Evaluating text generation with BERT.” ICLR 2020.
[66] Saad-Falcon, Jon, et al. “ARES: An automated evaluation framework for retrieval-augmented generation systems.” arXiv preprint (2023).
[67] Chen, Jiawei, et al. “Benchmarking large language models in retrieval-augmented generation.” AAAI 2024.
[68] Liu, Xiang, et al. “RECALL: A benchmark for LLMs robustness against external counterfactual knowledge.” arXiv preprint (2023).
[69] Lyu, Yuanjie, et al. “CRUD-RAG: A comprehensive Chinese benchmark for retrieval-augmented generation of large language models.” arXiv preprint (2024).
[70] Thakur, Nandan, et al. “BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models.” NeurIPS 2021.
[71] Petroni, Fabio, et al. “KILT: A benchmark for knowledge intensive language tasks.” NAACL 2021.
[72] Muennighoff, Niklas, et al. “MTEB: Massive text embedding benchmark.” EACL 2023.
[73] Liang, Xun, et al. “SafeRAG: Benchmarking security in retrieval-augmented generation.” arXiv preprint (2025).
[74] Wu, Kevin, Eric Wu, and James Zou. “ClashEval: Quantifying the tug-of-war between an LLM’s internal prior and external evidence.” arXiv preprint (2024).
[75] Chen, Danqi, et al. “Reading Wikipedia to answer open-domain questions.” ACL 2017.
[76] Zhu, Yinghao, et al. “REALM: RAG-Driven Enhancement of Multimodal Electronic Health Records Analysis via Large Language Models.” arXiv preprint (2024).
[77] Cui, Jiaxi, et al. “ChatLaw: Open-source legal large language model with integrated external knowledge bases.” arXiv preprint (2023).
[78] Shuster, Kurt, et al. “BlenderBot 3: A deployed conversational agent that continually learns to responsibly engage.” arXiv preprint (2022).
[79] Zhou, Shuyan, et al. “DocPrompting: Generating code by retrieving the docs.” ICLR 2023.
[80] Li, Jiatong, et al. “Empowering molecule discovery for molecule-caption translation with large language models: A ChatGPT perspective.” arXiv preprint (2023).
[81] Trivedi, Harsh, et al. “Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions.” ACL 2023.
[82] Wang, Liang, et al. “Query2Doc: Query expansion with large language models.” EMNLP 2023.
[83] Zheng, Huaixiu Steven, et al. “Take a step back: Evoking reasoning via abstraction in large language models.” ICLR 2024.
[84] Wang, Zhiruo, et al. “Learning to filter context for retrieval-augmented generation.” arXiv preprint (2023).
[85] Lee, Meng-Chieh, et al. “Agent-G: An agentic framework for graph retrieval augmented generation.” OpenReview (2024).
[86] Shen, Zhili, et al. “GeAR: Graph-enhanced agent for retrieval-augmented generation.” arXiv preprint (2024).
[87] Wu, Yusong, et al. “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation.” ICASSP 2023.
[88] Zhou, Junjie, et al. “MegaPairs: Massive data synthesis for universal multimodal retrieval.” arXiv preprint (2024).
[89] Arefeen, Md Adnan, et al. “iRAG: Advancing RAG for videos with an incremental approach.” arXiv preprint (2024).
[90] Wang, Dongsheng, et al. “DocLLM: A layout-aware generative language model for multimodal document understanding.” arXiv preprint (2024).
[91] Yuan, Zheng, et al. “RAMM: Retrieval-augmented Biomedical Visual Question Answering with Multi-modal Pre-training.” arXiv preprint (2023).
[92] Zhai, Yuanhang. “SAM-RAG: Multimodal retrieval augmented generation via self-adaptive multimodal retrieval.” arXiv preprint (2024).
[93] Yang, Qian, et al. “Enhancing Multi-modal and Multi-hop Question Answering via Structured Knowledge and Unified Retrieval-Generation.” arXiv preprint (2022).
[94] Li, Ye, et al. “OmniSearch: Adaptive search with an agentic retrieval pipeline.” arXiv preprint (2024).
[95] Khaliq, Varun, et al. “RAGAR: Reasoning-augmented generation for retrieval-augmented reasoning.” arXiv preprint (2024).
[96] Ma, Xueguang, et al. “VISA: Retrieval augmented generation with visual source attribution.” arXiv preprint (2024).
[97] Zhang, Xiang, et al. “AlphaFin: Benchmarking financial analysis with retrieval-augmented stock-chain framework.” arXiv preprint (2024).
[98] Wu, Junda, et al. “CoRAL: Collaborative retrieval-augmented large language models for recommendation.” arXiv preprint (2024).
[99] Gemini Team, Google. “Gemini: A family of highly capable multimodal models.” arXiv preprint (2024).
[100] TruLens. “TruLens: Evaluate and track LLM applications.” TruLens Documentation (2024).
[101] Lewis, Patrick, et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS 2020.
[102] Gao, Yunfan, et al. “Retrieval-Augmented Generation for Large Language Models: A Survey.” arXiv preprint (2023).
引用
引用:转载或引用本文内容时,请注明原作者和来源。
推荐引用格式:
Yue Shui. (Feb 2025). 检索增强生成 (RAG) 技术综述. https://syhya.github.io/zh/posts/2025-02-03-rag/
或使用 BibTeX:
@article{syhya2025rag,
title = "检索增强生成 (RAG) 技术综述",
author = "Yue Shui",
journal = "syhya.github.io",
year = "2025",
month = "Feb",
url = "https://syhya.github.io/zh/posts/2025-02-03-rag/"
}