Context management for long-horizon tasks and coordination across multiple execution units are among the central problems in current Agent research. In LLM Agents I introduced the three core modules of an Agent—planning, memory, and tool use; in Self-Evolving Agents and the FlashInfer Contest Summary I discussed the paradigm of Harness Engineering: humans design the constraints, feedback, and evaluation, while the Agent iterates inside a controlled closed loop to produce verifiable results. This post focuses on a more concrete layer of the problem: when tasks grow longer and more complex, what architecture should we use to organize an Agent?
Basic Concepts
Agent Skills, Subagents, Multi-Agent Systems, and Dynamic Workflows are often discussed together, but they are not the same kind of mechanism. More precisely, they map to four different system levels: capability encapsulation, execution isolation, collaborative organization, and runtime orchestration.
| Concept | System level | Design focus |
|---|---|---|
| Agent Skills | Capability encapsulation | Package stable, reusable operating procedures into standardized capabilities, reducing repeated planning and execution cost |
| Subagents | Execution isolation | Allocate independent context to relatively self-contained subtasks; the main agent delegates and collects results |
| Multi-Agent Systems | Collaborative organization | Organize multiple Agents to jointly complete complex tasks through role specialization, message passing, and coordination |
| Dynamic Workflows | Runtime orchestration | Dynamically schedule Skills, tools, and Subagents according to task state, intermediate results, and failure signals |
Workflow and Agent
Building Effective Agents (Anthropic, 2024) offers a widely cited distinction:
- Workflow: LLMs and tools are orchestrated through predefined code paths.
- Agent: the LLM dynamically and autonomously decides its own process and tool use, controlling how to accomplish the task.
The article’s core advice is: find the simplest solution first, and add complexity only when it is genuinely necessary. Many scenarios are well served by a single LLM call augmented with retrieval and in-context examples; there is no need to reach for a multi-agent system. The basic building block of every agentic system is an augmented LLM, i.e., a model equipped with retrieval, tools, and memory.
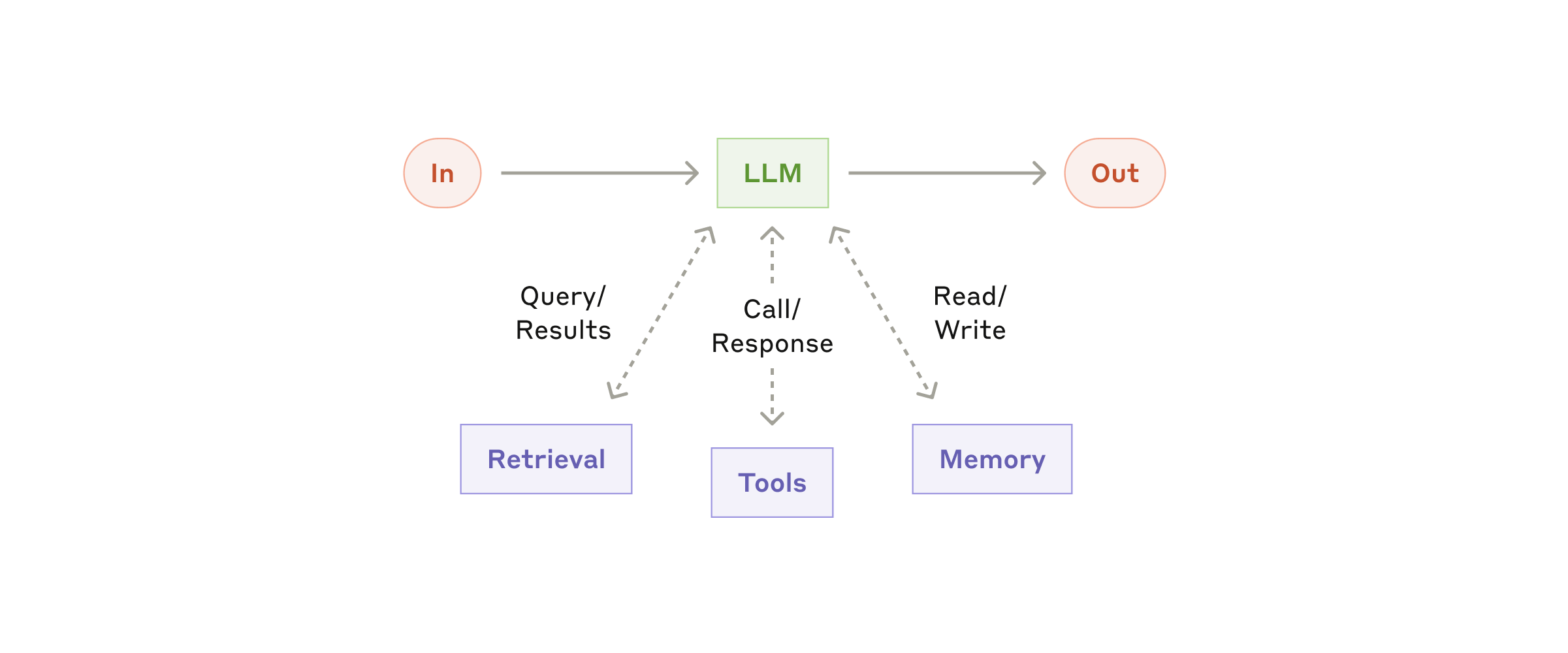
Fig. 1. The augmented LLM: the basic building block of agentic systems, enhanced with retrieval, tools, and memory. (Image source: Anthropic, 2024)
Understanding these basic workflows first matters because the Multi-Agent Systems and Dynamic Workflows discussed later build on them rather than replacing them. On top of the augmented LLM, the following five common composable workflow patterns are worth summarizing.
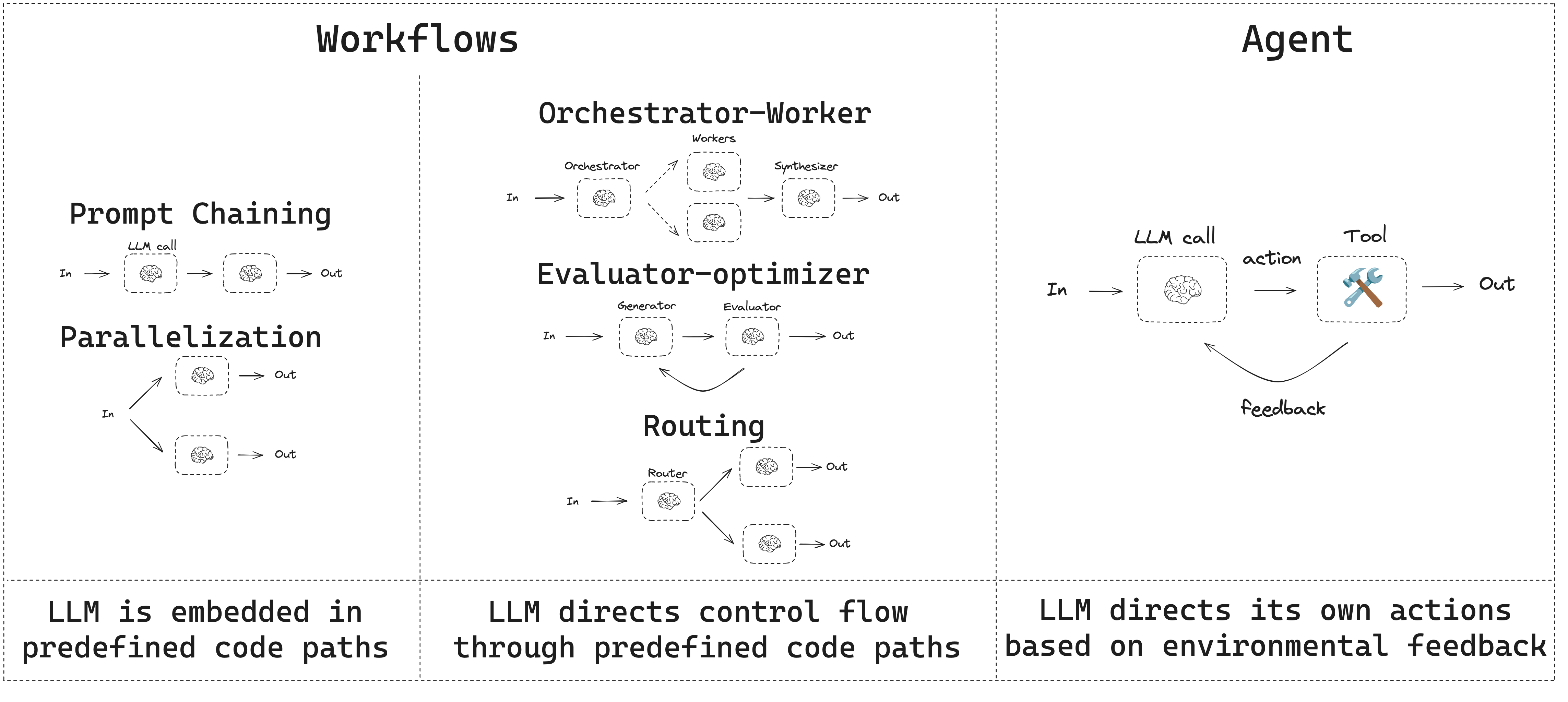
Fig. 2. Workflows orchestrate LLMs and tools along predefined code paths, while agents dynamically direct their own process and tool use. (Image source: LangGraph, 2025)
1. Prompt chaining: decompose a task into a sequence of ordered steps, where each LLM call processes the output of the previous one, with programmatic checks (gates) inserted in between. Suitable when a task can be cleanly broken into fixed subtasks.
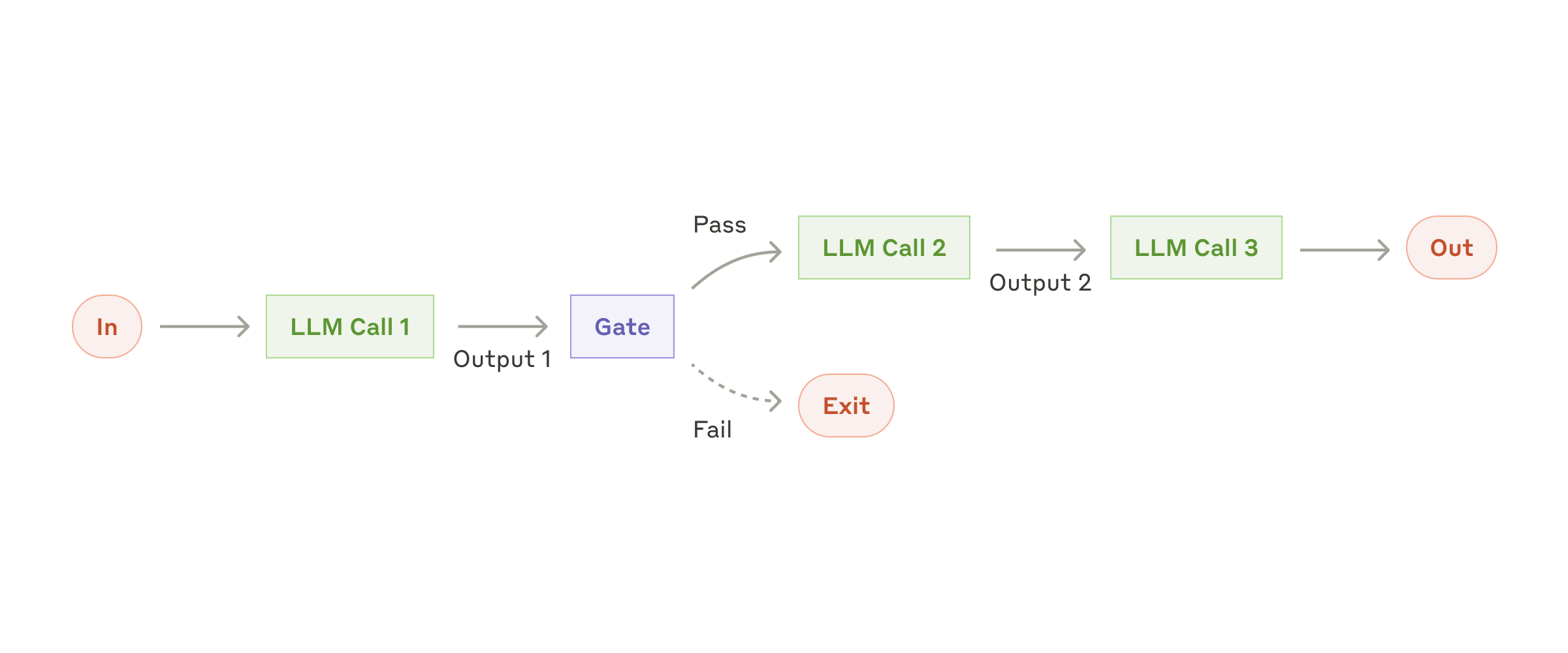
Fig. 3. The prompt chaining workflow. (Image source: Anthropic, 2024)
2. Routing: classify the input first, then direct it to specialized downstream handling. Suitable when input categories are distinct and handling them separately yields better results—this is precisely the prototype of the Classify-and-act pattern in Dynamic Workflows discussed later.
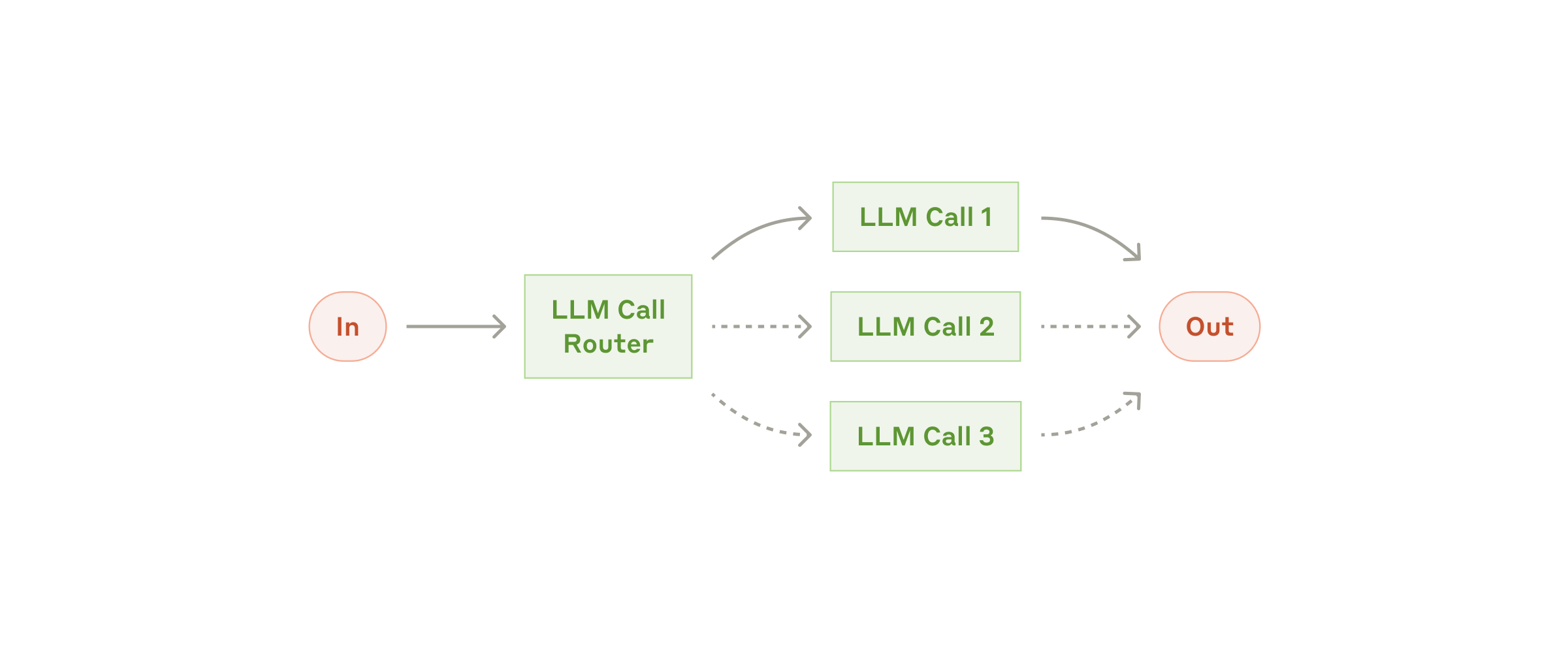
Fig. 4. The routing workflow. (Image source: Anthropic, 2024)
3. Parallelization: distribute a task in parallel, in two forms—sectioning (splitting into independent subtasks that run concurrently) and voting (running the same task multiple times to get diverse outputs). Suitable when work can be accelerated in parallel, or when multiple samples are needed to raise confidence.
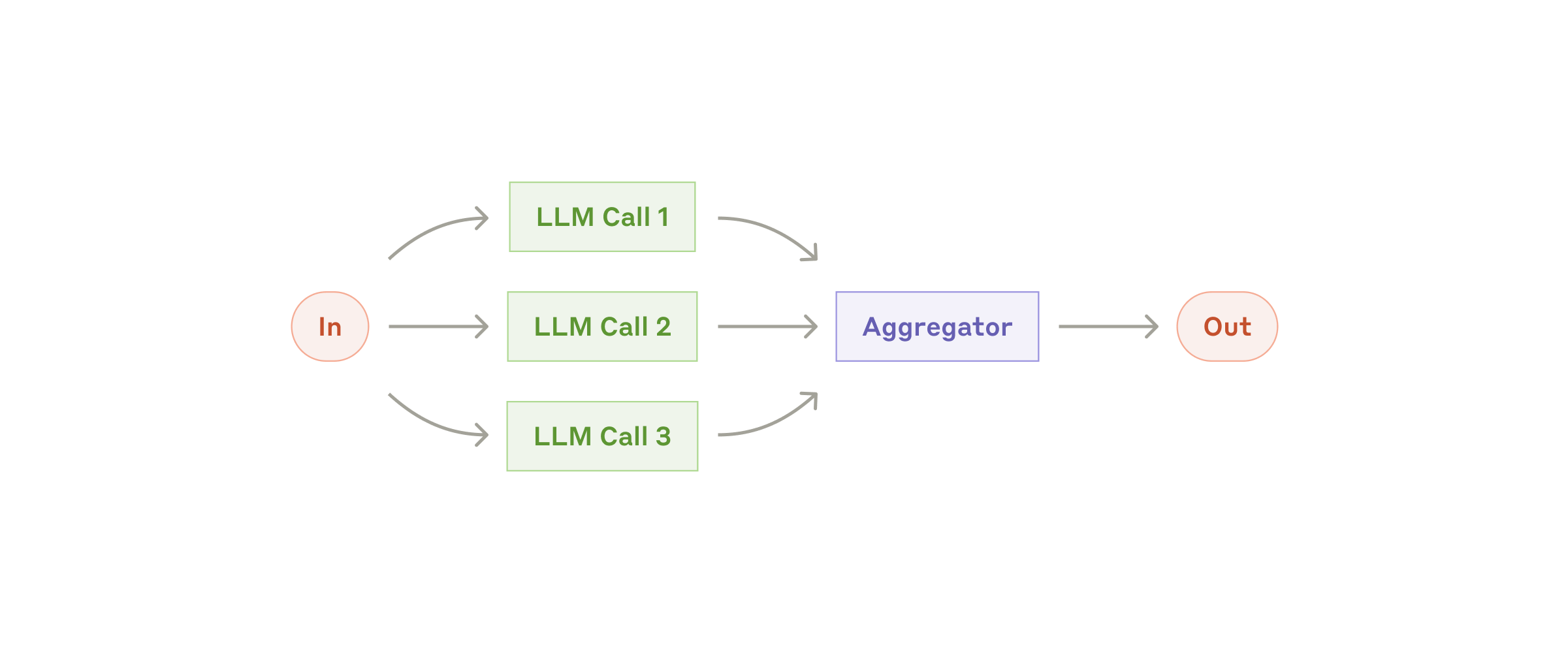
Fig. 5. The parallelization workflow. (Image source: Anthropic, 2024)
4. Orchestrator-workers: a central LLM dynamically decomposes a task, dispatches it to worker LLMs, and then synthesizes their results. The difference from parallelization is that the subtasks are not predefined but determined dynamically by the orchestrator based on the input.
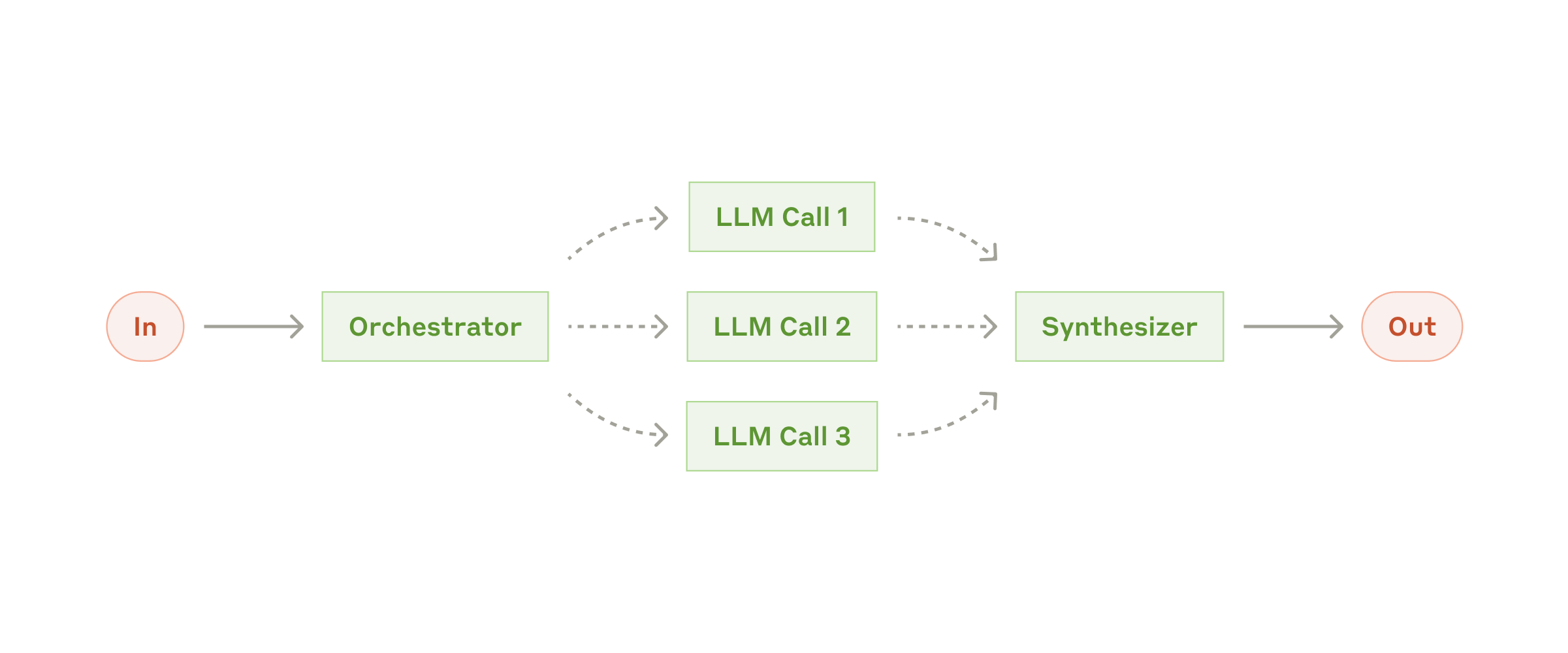
Fig. 6. The orchestrator-workers workflow. (Image source: Anthropic, 2024)
5. Evaluator-optimizer: one LLM generates a result while another evaluates it and provides feedback, iterating in a loop until satisfactory. Suitable when there are clear evaluation criteria and iteration brings noticeable improvement.
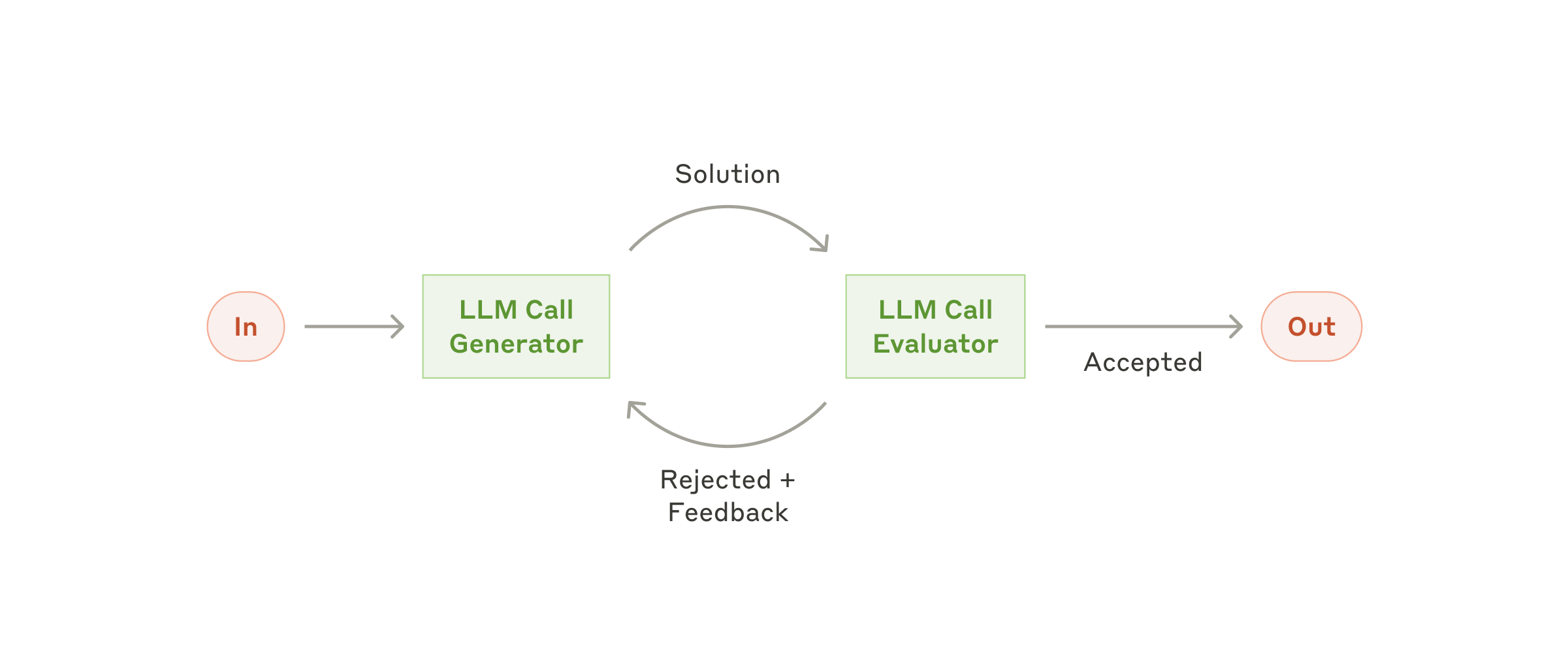
Fig. 7. The evaluator-optimizer workflow. (Image source: Anthropic, 2024)
When these predefined paths are no longer sufficient and the model needs to plan and decide on its own, we enter the realm of the true autonomous agent: the model uses tools autonomously in a loop, advancing based on environment feedback, until it completes the task or triggers a stopping condition.
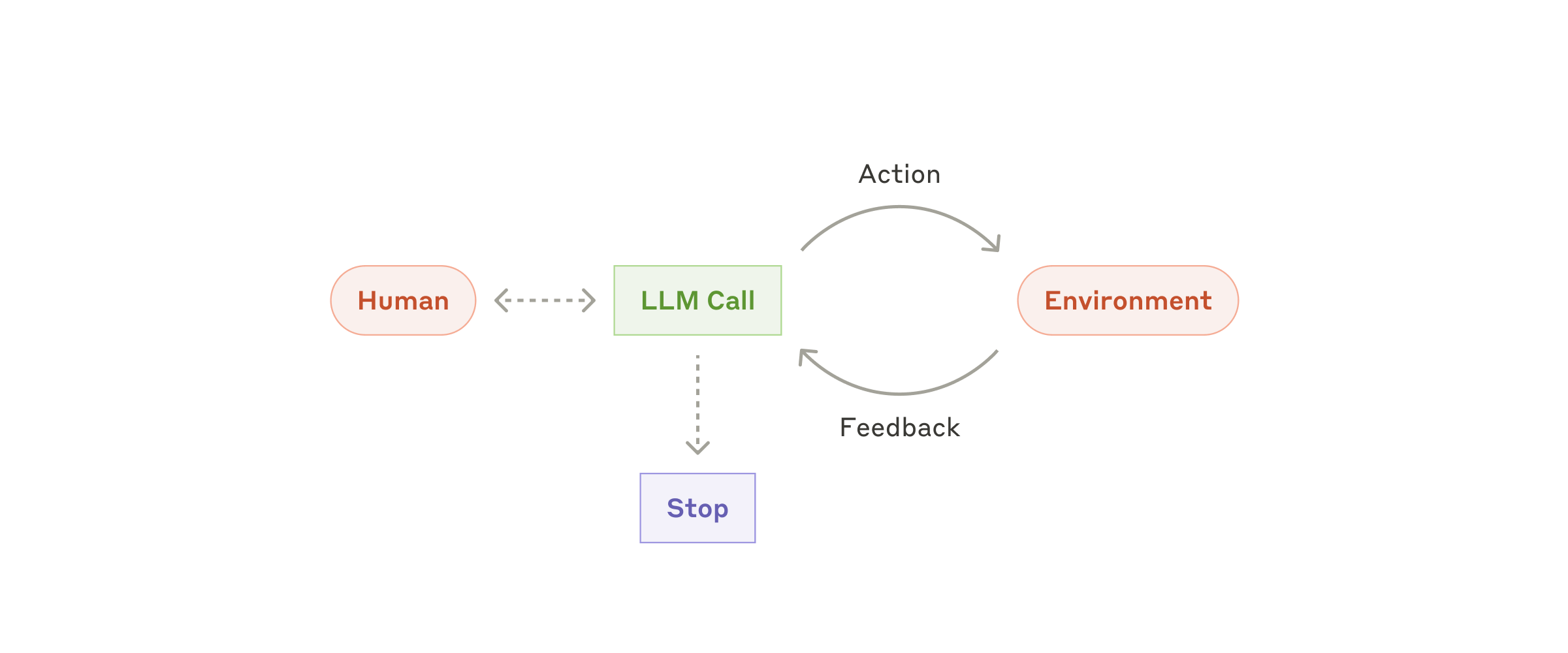
Fig. 8. Autonomous agent: the model plans, calls tools, and advances based on environment feedback in a loop. (Image source: Anthropic, 2024)
These five patterns can be viewed as atomic design patterns, while the Multi-Agent Systems and Dynamic Workflows discussed later in this post are the mechanisms that compose and schedule these atoms.
Context Window
An LLM’s effective working space is bounded by its context window. Context Rot (Hong et al., 2025) tested models including GPT-4.1, Claude 4, and Gemini 2.5 and found that performance does not stay consistent across different input lengths; as input grows longer, the model’s utilization of context gradually degrades and its output becomes more unstable. The figure below shows the declining trend of several mainstream models on the Repeated Words task as input length increases.
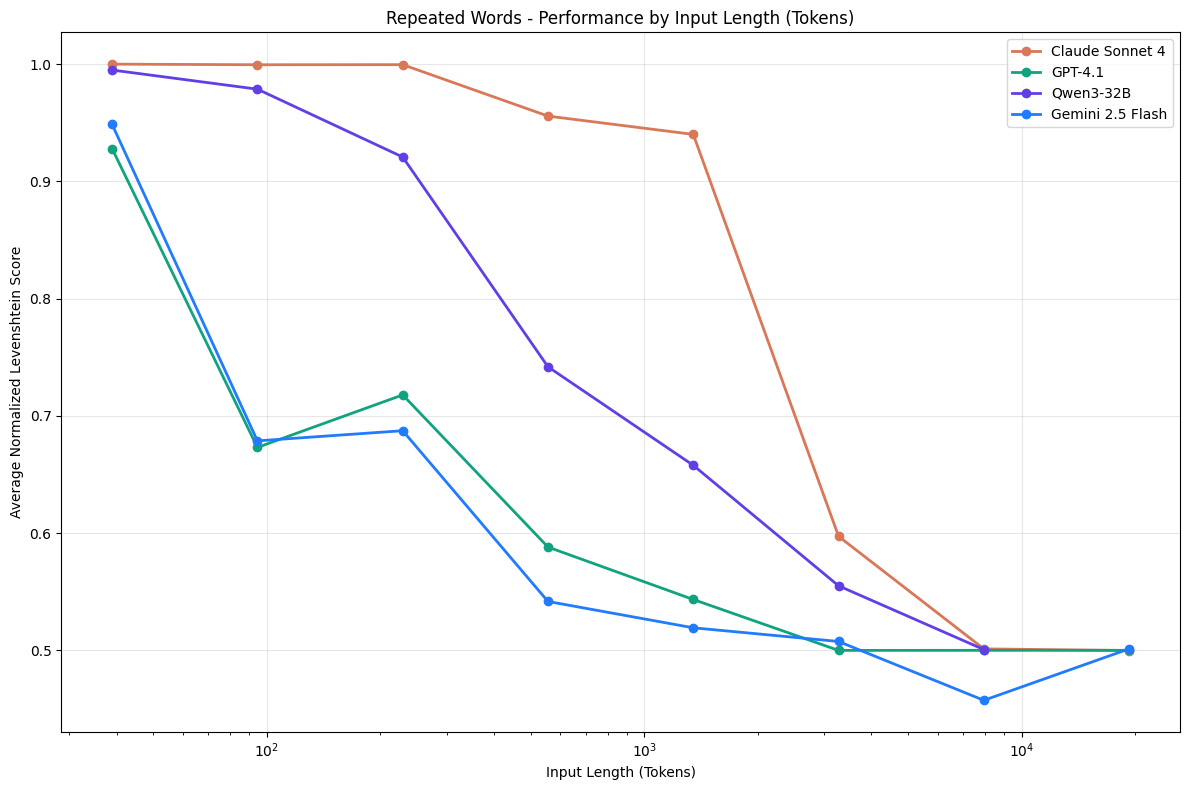
Fig. 9. Context Rot: model accuracy degrades as input length grows across Claude, GPT, Gemini, and Qwen families, showing that LLMs do not maintain consistent performance across input lengths. (Image source: Hong et al., 2025)
Context engineering (Anthropic, 2025a) differs from prompt engineering in that the latter usually refers to the discrete task of designing instructions once, whereas the former is a set of strategies for continuously curating, organizing, and maintaining context throughout the LLM’s inference process. It is not about writing one good prompt. It is about deciding, on every model call, which information to feed the model and which noise to drop, then updating that context as the task evolves. Its core goal is to construct, within as small a token budget as possible, the high-signal set of context that maximizes the probability of the desired output.
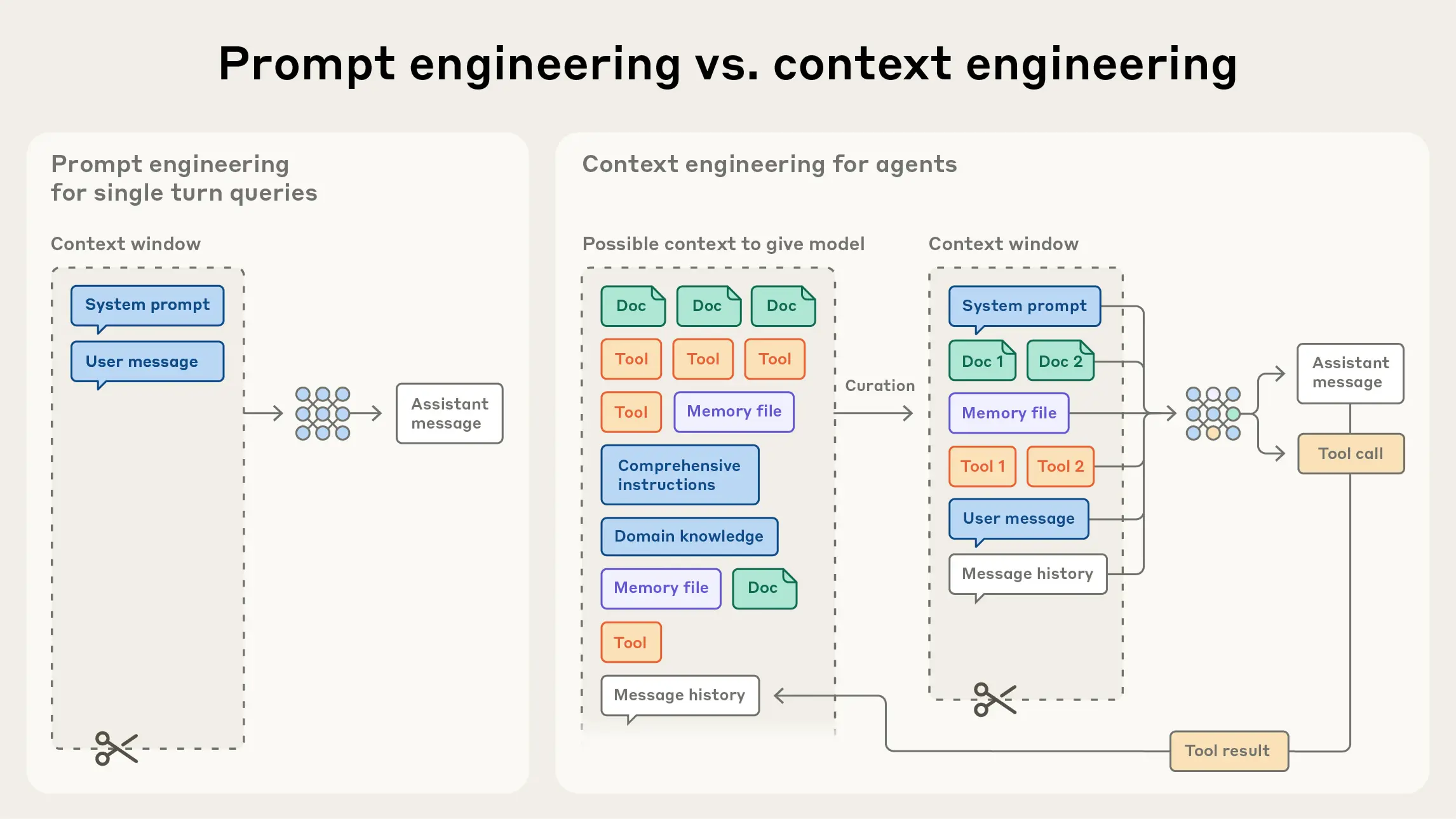
Fig. 10. Context engineering treats the context window as a finite resource: system prompts, tools, message history, and retrieved data must all be curated into the smallest high-signal set that fits within the model’s attention budget. (Image source: Anthropic, 2025a)
For long-horizon tasks, there are three categories of approaches:
- Compaction: when a conversation approaches the context limit, summarize its contents and restart a fresh context window, preserving architectural decisions and unresolved problems while discarding redundant tool outputs.
- Structured note-taking: the Agent persists notes outside the context window (e.g.,
NOTES.md, a to-do list) and reads them back when needed. - Subagent architecture: dedicated Subagents handle focused tasks in a clean context and return a compressed summary (typically 1,000–2,000 tokens) to the coordinating main agent.
These long-horizon strategies set up the three mechanisms this post covers next: Skills reduce repeated instructions entering the context through on-demand loading, Subagents avoid polluting the main context with intermediate material through isolated execution, and Dynamic Workflows compose both into a controllable long-horizon execution graph. Let’s begin with the lightest-weight mechanism—Skills.
Agent Skills
An Agent Skill (Anthropic, 2025b) packages a set of reusable instructions, metadata, and optional resources (scripts, templates, reference materials) into a modular capability. Claude invokes it automatically when it judges the skill relevant to the current request. The difference from a prompt is that a prompt is a one-off, conversation-level instruction, whereas a Skill is a capability loaded on demand from the file system, sparing you from repeatedly pasting the same prompt across multiple conversations.
SKILL.md Structure
Each Skill is a folder on the file system, with the SKILL.md file at its core. It consists of two parts: a YAML frontmatter at the top (telling the model what this skill does and when to use it), followed by the Markdown instruction body. The frontmatter has only two required fields, name and description, with the following constraints:
name: at most 64 characters, only lowercase letters, digits, and hyphens; cannot contain XML tags, and cannot contain the reserved wordsanthropicorclaude.description: non-empty, at most 1024 characters, cannot contain XML tags; it should describe both what the skill does and when Claude should use it, since this is exactly what Claude relies on to decide whether to trigger the skill.
Beyond the body, a Skill can optionally bundle additional Markdown instruction files, executable scripts, and reference materials (such as database schemas, API documentation, templates).
pdf-skill/
├── SKILL.md # Required: YAML frontmatter + Markdown instructions
├── FORMS.md # Optional: supplementary instructions (e.g., form-filling guide)
├── REFERENCE.md # Optional: detailed API reference
└── scripts/
└── fill_form.py # Optional: a script Claude executes via bash
Progressive Disclosure
The most elegant aspect of Skill design is progressive disclosure: a Skill runs in an environment with a file system, bash, and code execution, and Claude loads content in tiers, on demand—like consulting a specific section of an onboarding guide—rather than stuffing everything into the context at once. The three categories of Skill content map to three loading levels:
| Level | Content type | Loaded when | Context footprint | What is loaded |
|---|---|---|---|---|
| Level 1 / Metadata | Instructions | At startup (always) | ~100 tokens / skill | The name and description in the YAML frontmatter |
| Level 2 / Instructions | Instructions | When the skill is triggered | < 5k tokens | The workflows and guidance in the SKILL.md body |
| Level 3+ / Resources | Instructions, code, resources | On demand | Nearly unlimited | Bundled files read/executed via bash; contents do not enter the context |
The key to this mechanism is: the contents of SKILL.md are read from the file system and enter the context window via bash only when they are actually needed. If the instructions reference a file like FORMS.md, Claude reads it in via bash only then; and when the instructions mention a script, Claude runs it via bash and receives only the script’s output (e.g., “validation passed”)—the script code itself never enters the context.
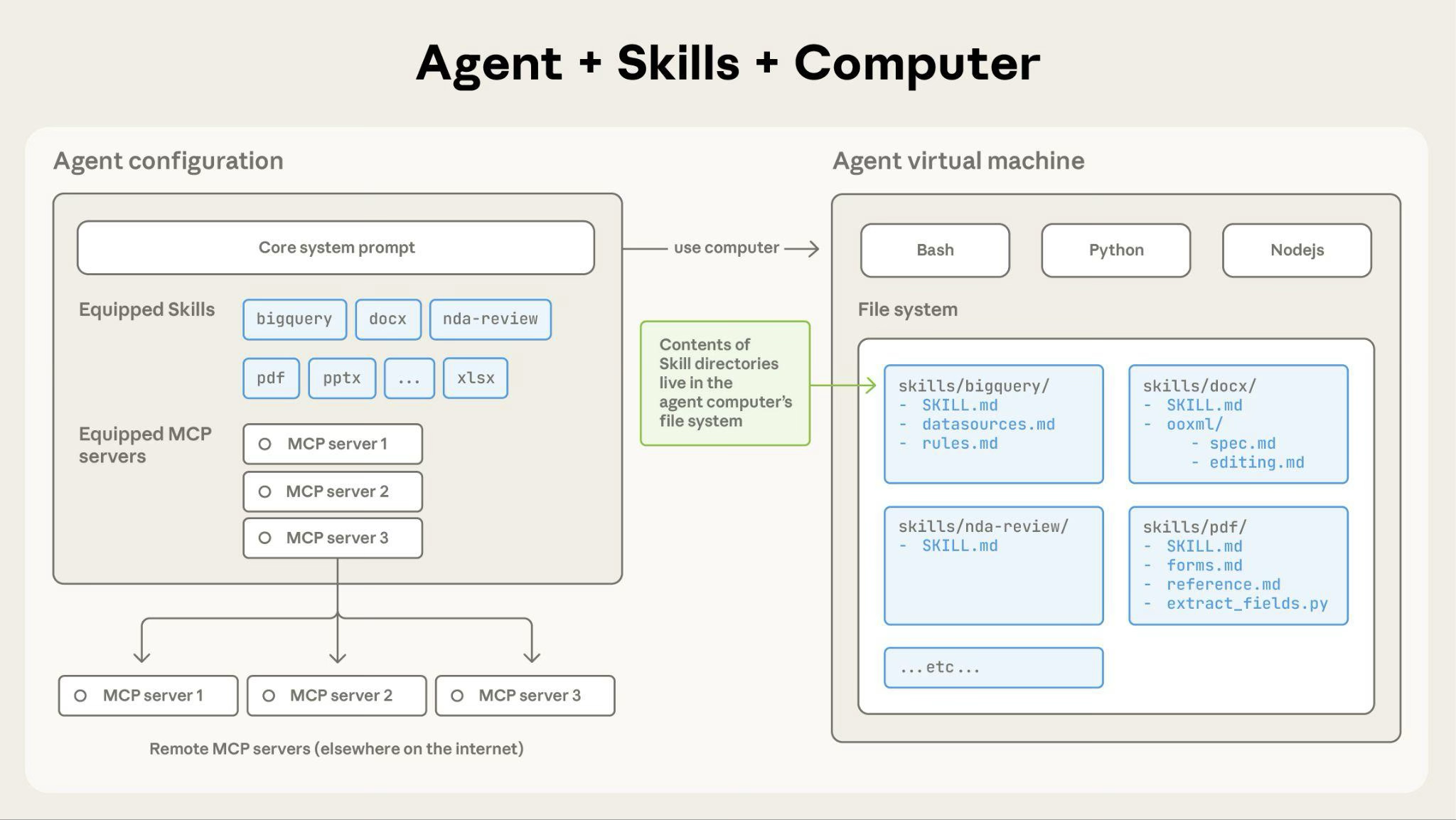
Fig. 11. Progressive disclosure in Agent Skills: at startup only each Skill’s name/description metadata (~100 tokens) sits in the system prompt; the full SKILL.md body loads into context only when the Skill is triggered; bundled files and scripts are read or executed via bash on demand without their contents entering the context window. (Image source: Anthropic, 2025c)
This brings three direct benefits:
- On-demand file access: a Skill can contain dozens of reference files, but a task reads only whichever it needs; the rest stay on the file system, consuming zero tokens.
- Efficient script execution: script code does not enter the context, which saves far more tokens than having the model generate equivalent code on the spot.
- Almost no upper bound on bundled content: because files consume no context until accessed, a Skill can package large amounts of API documentation, datasets, or examples without incurring any context burden.
Subagents and Agent Teams
Subagents
Subagents (Anthropic, 2026a) solve the problem of context isolation. When an auxiliary task produces a large volume of search results, logs, or file contents that need not be referenced directly in the main conversation afterward, it should be handed to a Subagent to avoid cluttering the main context and triggering Context Rot.
A Subagent is an executor with its own independent context window: it completes exploration, reading, and reasoning in its own context, returning only the compressed conclusion to the main Agent. This mechanism is especially well-suited to complex tasks such as codebase exploration and multi-step feature planning, because it keeps the main Agent focused while isolating large amounts of intermediate process in a separate context. Its core value includes:
- Preserve context: isolate exploration and implementation details outside the main conversation, keeping the main context focused.
- Enforce constraints: limit the tools and skills a Subagent can use.
- Reuse configurations: reuse configurations across multiple projects via user-level Subagents.
- Specialize behavior: use a focused system prompt to make a Subagent specialize in a particular domain.
- Control costs: route tasks to faster or lower-cost models (such as Sonnet or the GPT mini series).
Claude Code gives an intuitive example: a Subagent reads 6,100 tokens of files in its own context but returns only a 420-token result summary to the main Agent.
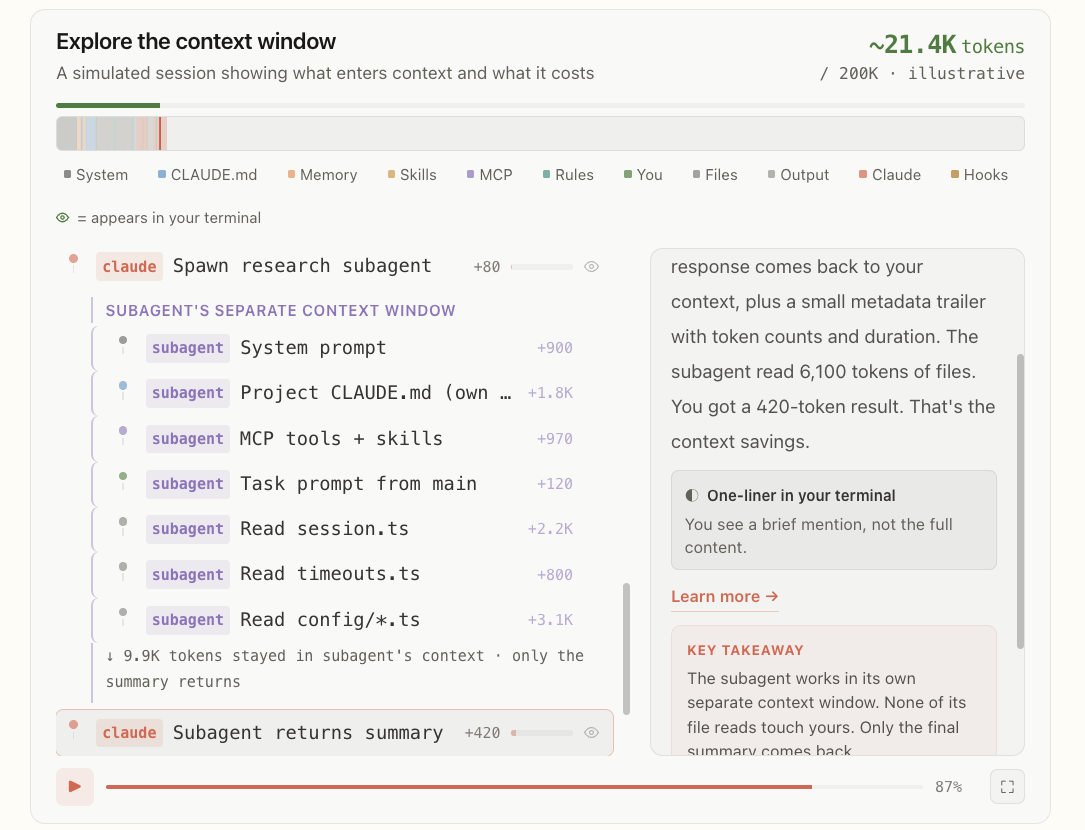
Fig. 12. A subagent works in its own context window: it reads 6,100 tokens of files but returns only a 420-token summary to the main agent, keeping the raw intermediate content out of the main conversation. (Image source: Anthropic, 2026b)
Agent Teams
Subagents are just one of Claude Code’s parallel capabilities; they only report to the main Agent and never communicate with one another. When a task requires multiple executors to discuss and coordinate with each other, it is time for Agent Teams (Anthropic, 2026c): multiple sessions, each with its own context, share a task list, claim work themselves, and communicate directly, all coordinated by a lead agent. Both have independent contexts, but their modes of collaboration are entirely different:
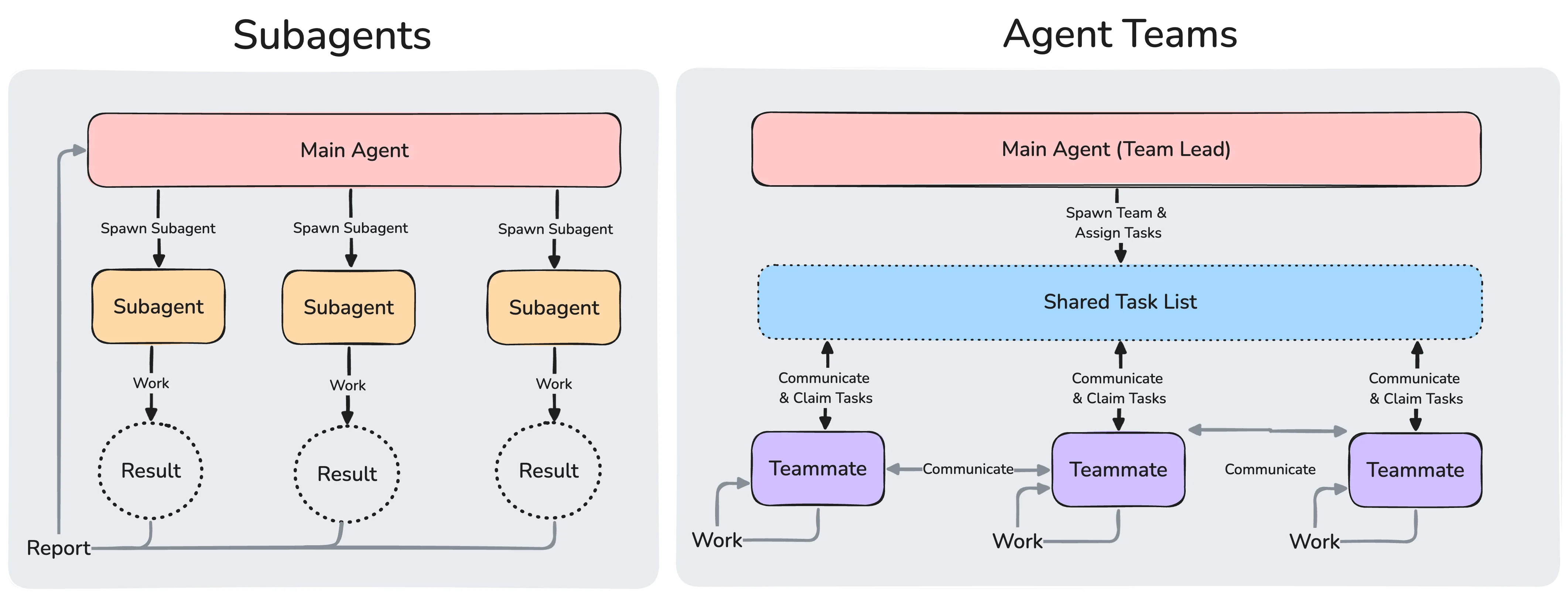
Fig. 13. Subagents only report results back to the main agent and never talk to each other; in agent teams, teammates share a task list, claim work, and communicate directly. (Image source: Anthropic, 2026c)
| Subagents | Agent Teams | |
|---|---|---|
| Context | Independent context window; results returned to the caller | Independent context window; fully independent |
| Communication | Only reports results to the main Agent | Teammates communicate directly with one another |
| Coordination | The main Agent manages all work | A shared task list, self-coordinated |
| Suited for | Focused tasks where only the result matters | Complex work requiring discussion and collaboration |
| Token cost | Lower: a summary returned to the main context | Higher: each teammate is an independent Claude instance |
Subagents are workers temporarily dispatched by the main Agent, while Agent Teams are more like a collaborative space composed of multiple long-running sessions.
Multi-Agent Systems
When a complex problem can be split into multiple relatively independent directions to be explored in parallel, a single Subagent is no longer enough; an orchestrator is needed to organize a group of Subagents. This is the Multi-Agent System, whose most classic form is the Orchestrator-Worker pattern.
In How We Built Our Multi-Agent Research System (Anthropic, 2025d), Anthropic describes in detail the architecture of its Research feature.
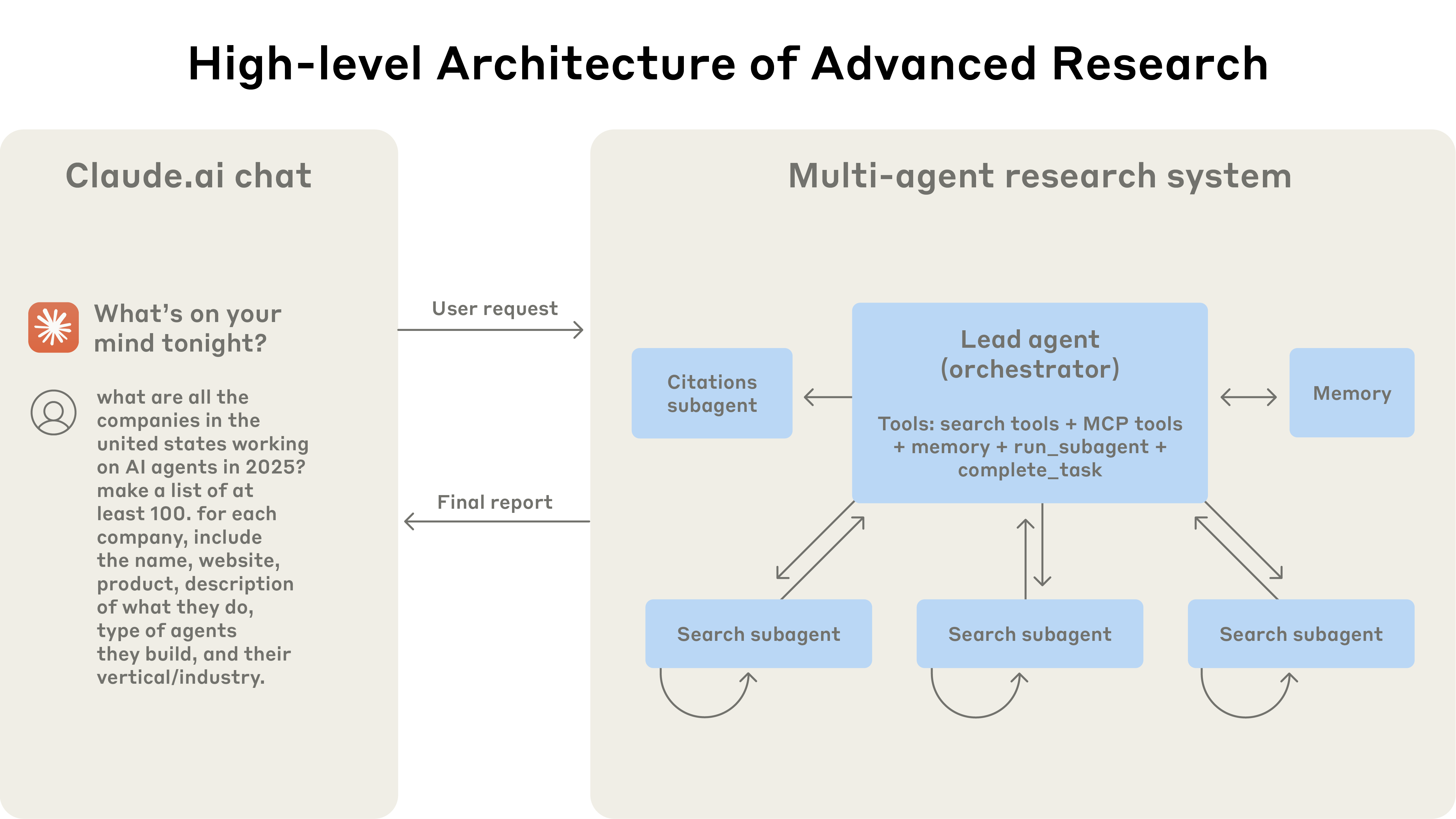
Fig. 14. High-level architecture of Anthropic’s multi-agent research system: user queries flow through a lead agent that creates specialized subagents to search in parallel, then synthesizes results. (Image source: Anthropic, 2025d)
This is a typical orchestrator-worker multi-agent architecture: a lead agent coordinates the whole process and delegates tasks to specialized Subagents running in parallel, and finally a CitationAgent processes the documents and research report to identify specific locations for citations. The full execution flow is shown below:
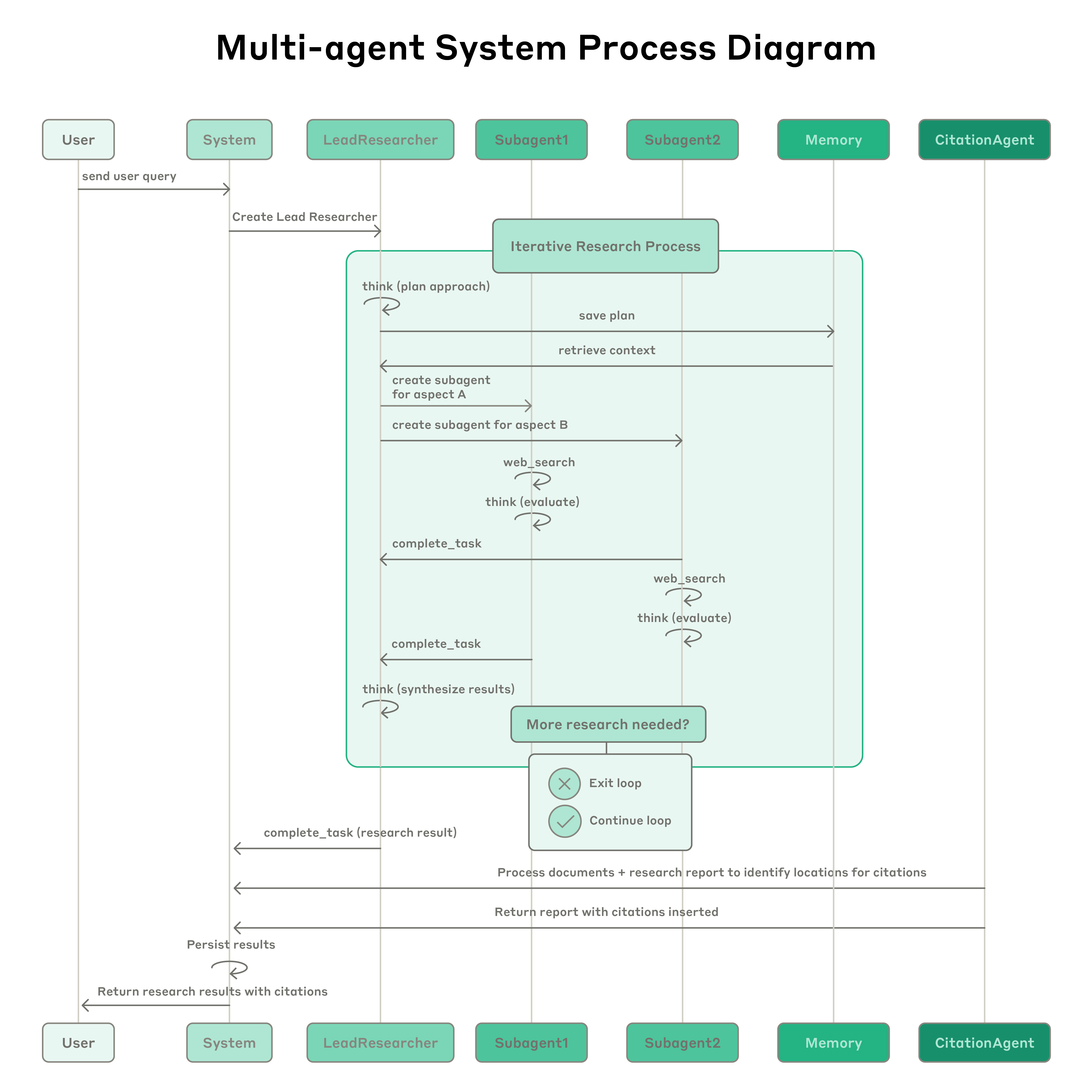
Fig. 15. The full process of the multi-agent research system: the LeadResearcher plans and spawns subagents, which retrieve in parallel and return results, and finally the CitationAgent aligns citation locations to produce the report. (Image source: Anthropic, 2025d)
Why are research tasks especially well-suited to Multi-Agent? Research is open-ended and path-dependent, so its process is hard to hard-code: you have to adjust direction while searching. It also decomposes naturally into independent sub-directions. And search is essentially compression—distilling key tokens from a large number of web pages—so giving each Subagent its own context window to explore and return a small, high-value summary fits the problem well.
A multi-agent system using Claude Opus 4 as the lead agent and Claude Sonnet 4 as Subagents outperformed a single-agent Claude Opus 4 by 90.2% on Anthropic’s internal research eval. But the gains come with significant cost. Anthropic’s empirical observation is that ordinary Agent systems consume roughly 4× the tokens of chat, while Multi-Agent Systems consume roughly 15× the tokens. Multi-Agent is suited to high-value, highly parallel tasks whose information volume exceeds a single context window—not to every task.
The effectiveness of a Multi-Agent System depends heavily on the lead agent’s task-decomposition ability and the design of the delegation prompt. The lead agent needs to tell each Subagent clearly what the research objective is, what the search scope is, which sources to focus on, which directions not to duplicate, and in what format to return the final result. If the division of labor is unclear, multiple Subagents may search the same batch of information repeatedly, or miss key directions, which actually drives up the cost of synthesis.
Dynamic Workflows
Claude Code provides a general-purpose coding harness by default, letting the model plan, execute, check, and summarize within a single context. For ordinary coding tasks, this is usually sufficient; but when tasks grow longer, parallelism increases, structure becomes more complex, or strong verification is required, a single context easily spirals out of control: the model must remember the original goal while also maintaining intermediate state, handling large volumes of tool results, and judging whether each branch is complete.
The core idea of Dynamic Workflows (Anthropic, 2026d) is: let Claude dynamically generate a dedicated harness for the current task at runtime, rather than forcing one Agent to push through an entire complex task in a single context. This harness is typically a piece of JavaScript code used to spawn, coordinate, and manage multiple Subagents. In other words, Claude not only executes the task but also generates an executable workflow for it on the fly.
What Dynamic Workflows aim to solve are precisely the failure modes that recur in long-horizon tasks within a single context:
| Failure mode | Meaning |
|---|---|
| Agentic laziness | Facing a complex, multi-part task, Claude stops before finishing and declares the job done after only partial progress |
| Self-preferential bias | When asked to verify or judge against a rubric, Claude tends to prefer its own results or findings |
| Goal drift | Across many turns—especially after context compaction—Claude gradually loses fidelity to the original objective |
All three problems are fundamentally tied to the single context: planning, execution, verification, and correction all live together, and the model is easily influenced by intermediate results. Dynamic Workflows separate these steps through independent Subagents and explicit workflow control: each Subagent focuses only on a local objective, while the workflow is responsible for maintaining global state, concurrent scheduling, result verification, and stopping conditions. They therefore act more like a runtime scheduler built on top of Subagents.
Viewing it alongside Subagents and Agent Teams, the three represent different orientations of Claude Code’s parallel work:
| Approach | What it provides | When to use |
|---|---|---|
| Subagents | A delegated worker within a session that completes a side task in its own context and returns a summary | A side task produces large volumes of search results, logs, or file contents that are not referenced directly afterward |
| Agent Teams | Multiple coordinated sessions that share a task list, communicate with each other, and are managed by a lead | You need to split a project into chunks, distribute them, and keep multiple workers in sync |
| Dynamic Workflows | A script orchestrating multiple Subagents, scheduling and cross-checking their results | A task is too large to coordinate turn-by-turn manually, or needs explicit verification and stopping conditions |
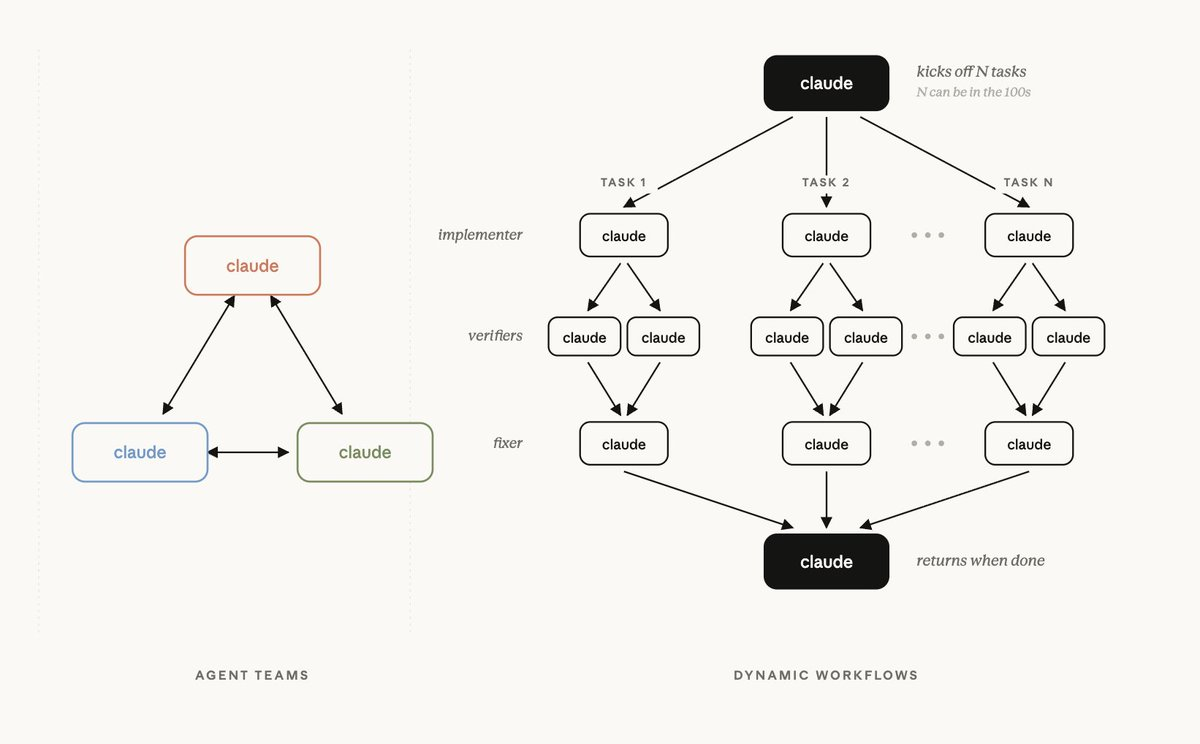
Fig. 16. Claude Code parallelizes work in several ways: subagents delegate a side task in their own context and return only a summary, agent teams coordinate through a shared task list with direct messaging, and dynamic workflows script and cross-check many subagents for jobs too big to coordinate one turn at a time. (Image source: Cat Wu on X)
Workflow Patterns
Anthropic summarizes several common workflow patterns. When Claude generates a harness at runtime, it may use one of them alone or combine several patterns.
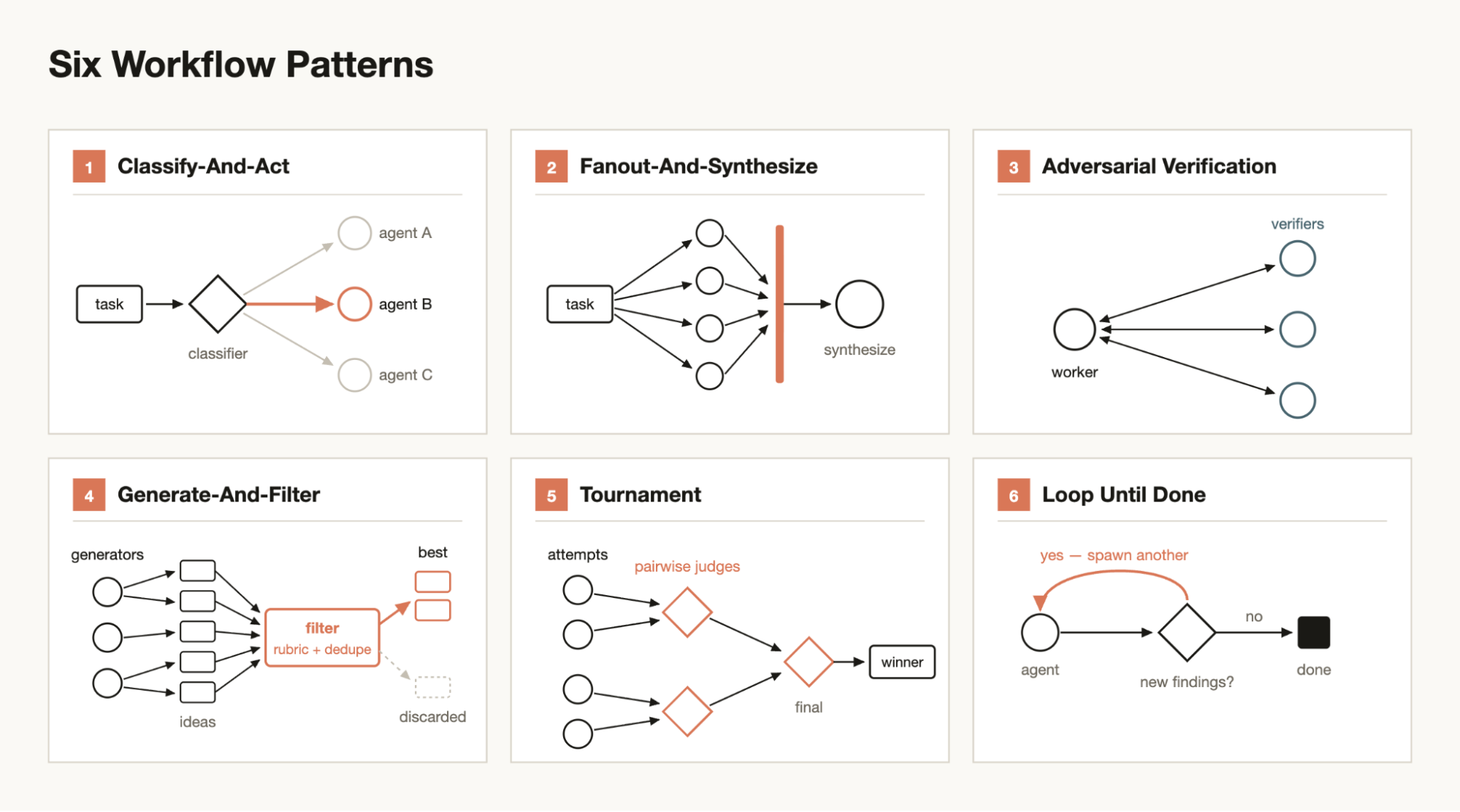
Fig. 17. Six common dynamic workflow patterns in Claude Code: classify-and-act, fan-out-and-synthesize, adversarial verification, generate-and-filter, tournament, and loop until done. (Image source: Anthropic, 2026d)
| Pattern | Applicable scenario | Core idea |
|---|---|---|
| Classify-and-act | Task type is uncertain, or output needs routing | Use a classifier agent to determine the task type first, then route to different agents or behaviors |
| Fan-out-and-synthesize | Many splittable small tasks | Split the task into multiple independent steps run in parallel; a synthesize step then waits for all to finish and merges structured results |
| Adversarial verification | High confidence or strict verification required | Spawn an independent verifier agent for the generated result, adversarially checking the output against a rubric or criteria |
| Generate-and-filter | Ideation, naming, solution exploration | Generate many candidates first, then filter against a rubric or verification, deduplicate, and keep only high-quality results |
| Tournament | Subjective ranking, solution selection, or quality comparison | Have multiple agents complete the same task with different approaches, then select winners round by round via pairwise judging |
| Loop until done | Workload is unknown, the number of rounds cannot be preset | Keep generating or checking until a stopping condition is met, e.g., no new findings or no new errors in the logs |
The value of these patterns lies in moving coordination out of the model’s single context and handing it to explicit workflow control. Taking /deep-research as an example: one can first use fan-out-and-synthesize to have multiple Subagents separately verify papers, product documentation, and blog sources; then use adversarial verification to check each conclusion against a rubric of citations, dates, numbers, etc.; and finally have the synthesizer merge only the content that passes verification. In this way, Dynamic Workflows turn parallel exploration, adversarial verification, and final synthesis into explicit execution constraints.
Agent Scaling Laws
The preceding sections introduced increasingly complex modes of organization, but one key question remains unresolved: is more Agents always better? Towards a Science of Scaling Agent Systems (Kim et al., 2025) evaluates 260 experimental configurations, covering 6 agentic benchmarks (BrowseComp-Plus, Finance-Agent, Plancraft, WorkBench, SWE-bench Verified, Terminal-Bench), 5 architectures (single-agent plus four multi-agent types: Independent / Centralized / Decentralized / Hybrid), and 3 LLM families (OpenAI, Google, Anthropic). The core conclusion is: adding more Agents is not universally beneficial; whether it helps depends on task structure, especially the task’s parallelism vs. sequentiality, tool density, and decomposability.
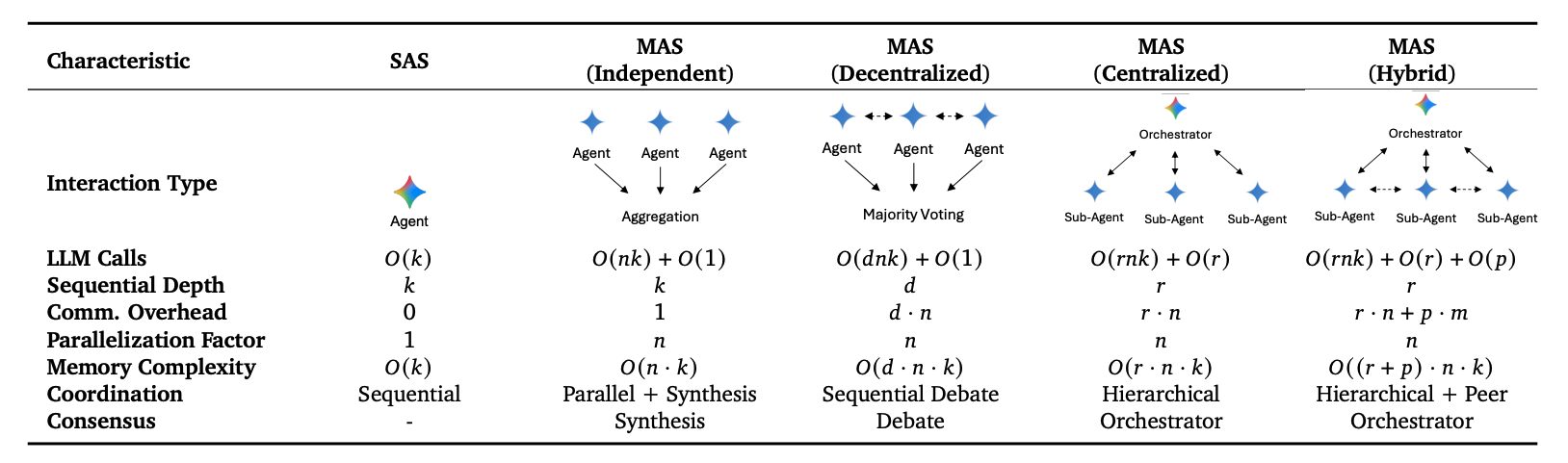
Fig. 18. The agent system architectures studied: a single-agent baseline alongside several multi-agent coordination topologies. (Image source: Kim et al., 2025)
Several key findings:
- Parallelizable → benefits; sequential reasoning → harmed: multi-agent coordination brings gains on parallelizable tasks, but harms performance on sequential tasks that require step-by-step reasoning. Relative to the single-agent baseline, the range of performance change spans from +80.8% on a decomposable financial reasoning task (centralized coordination) to −70.0% on a sequential planning task (independent coordination), because communication overhead fragments the reasoning process.
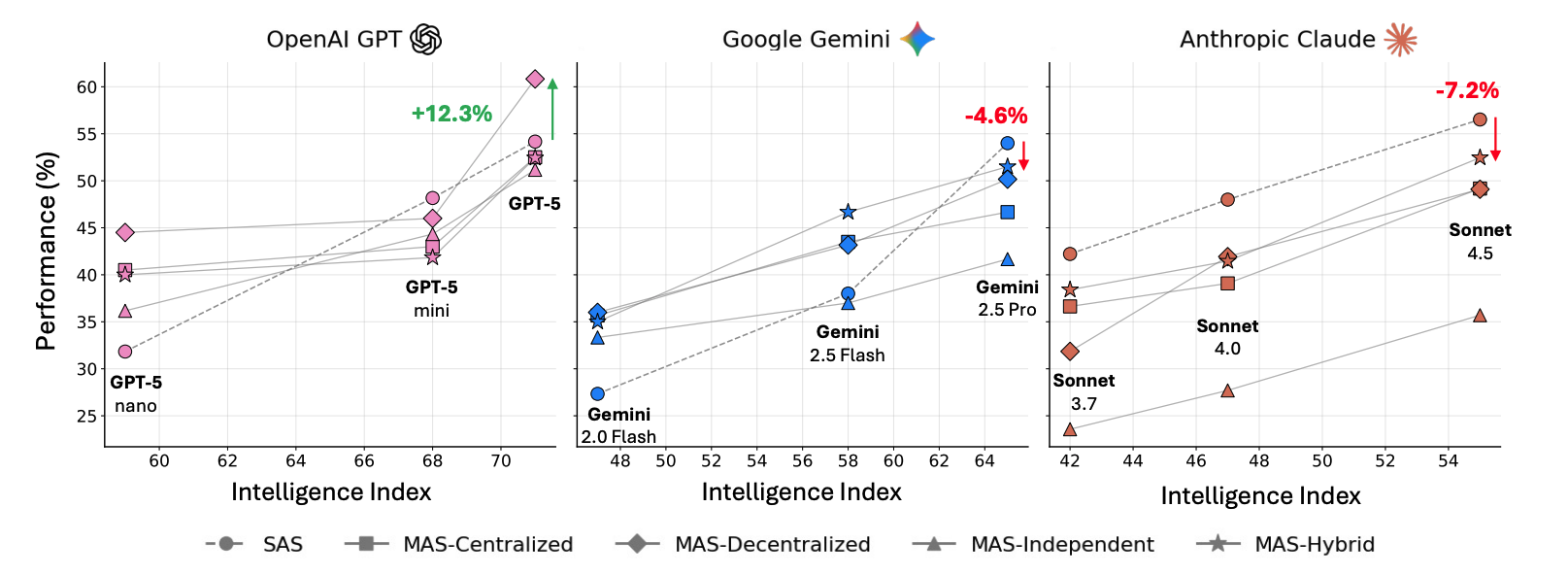
Fig. 19. Multi-agent coordination helps on parallelizable tasks but hurts on sequential ones, and the benefit shrinks as the single-agent baseline grows stronger (capability saturation). (Image source: Kim et al., 2025)
- Capability-saturation effect: once the single-agent baseline accuracy exceeds a threshold of about 45%, adding more agents yields negative returns. In other words, the stronger the model, the lower the relative value of multi-agent.
- Architecture determines error propagation: an Independent system without centralized verification amplifies trace-level errors by up to 17.2×, whereas a Centralized orchestrator, by acting as a “verification bottleneck,” keeps the amplification at 4.4× (decentralized 7.8×, hybrid 5.1×, single-agent baseline 1.0×). The paper adds an important caveat. After controlling for coordination efficiency and overhead, the error-amplification effect is not statistically significant; the differences across architectures stem more from coordination overhead than from pure error propagation.
Decision Guidance
To converge all the preceding mechanisms into an actionable decision rule, you can judge in order along five questions:
- Is the process stable and used repeatedly? If so, prefer encapsulating it as an Agent Skill.
- Will the subtask produce large amounts of intermediate information that pollutes the main context? If so, hand it to a Subagent.
- Is the task naturally parallelizable, with an information volume that exceeds a single context window? If so, consider a Multi-Agent System.
- Do you need strong verification, automatic scheduling, or repeatable control logic? If so, introduce Dynamic Workflows.
- If the task is strongly sequentially dependent, or a single Agent is already strong enough, keep a Single Agent—do not add complexity for complexity’s sake.
| Judgment | Recommended mechanism | Typical scenario | Why |
|---|---|---|---|
| Repeated process already standardized | Agent Skill | Fixed checklists, project conventions, fixed operations | The point is that “how to do it” is fixed, so encapsulate it into a reusable process |
| Independent task pollutes the context | Subagents | Heavy search, complex analysis, massive intermediate information | The point is to isolate the task and avoid Context Rot |
| Fixed role reused over the long term | Custom Subagents | Fixed permissions, fixed tools, long-term reuse | Not only the process is fixed; “who does it” is also fixed |
| Standard process + independent execution | Subagents + Skill | A dedicated role executing a standardized process | Subagents handle isolation and permissions, Skill handles the standardized process |
| Parallelizable, information exceeds a single context | Multi-Agent System | Open-ended research, parallel multi-direction exploration | The orchestrator splits and schedules, the workers compress in parallel |
| Task too large to coordinate manually / strong verification needed | Dynamic Workflows | Large-scale migration, fact-checking, security review, root cause | Runtime dynamic orchestration + adversarial verification |
| Strongly sequential reasoning / single agent already strong enough | Single Agent | Chain-of-thought reasoning, planning, simple coding | Multi-agent communication overhead fragments the reasoning instead of helping it |
In complex scenarios, the most powerful setups often combine several mechanisms. For example, in a code-migration task, the workflow creates a Subagent for each module, each Subagent invokes a migration checklist skill to complete local modifications, then a verifier agent checks tests and edge conditions, and finally the main agent merges the results.
Dynamic Workflows
├── Subagent A + Skill X
├── Subagent B + Skill Y
├── Verifier Agent (adversarial verification)
└── Synthesizer (synthesis)
Summary
The key to Agent architecture design is not stacking up more Agents, but matching task structure to system complexity. Skills solve reusable processes, Subagents solve context isolation, Multi-Agent Systems solve parallel division of labor, and Dynamic Workflows solve runtime orchestration and verification. The harder skill is restraint: reach for the lightest mechanism the task structure actually demands, and add a heavier one only when a concrete failure—context pollution, unmanageable parallelism, weak verification—forces your hand.
References
[1] Anthropic (Schluntz, Erik, and Barry Zhang). “Building Effective Agents.” Anthropic Engineering Blog (2024).
[2] LangGraph. “Workflows and Agents.” LangGraph Tutorial (2025).
[3] Hong, Kelly, Anton Troynikov, and Jeff Huber. “Context Rot: How Increasing Input Tokens Impacts LLM Performance.” Chroma Technical Report (2025).
[4] Anthropic. “Effective Context Engineering for AI Agents.” Anthropic Engineering Blog (2025a).
[5] Anthropic (Zhang, Barry, Keith Lazuka, and Mahesh Murag). “Equipping Agents for the Real World with Agent Skills.” Anthropic Engineering Blog (2025b).
[6] Anthropic. “Agent Skills Overview.” Claude Platform Documentation (2025c).
[7] Anthropic. “Subagents.” Claude Code Documentation (2026a).
[8] Anthropic. “Explore the Context Window.” Claude Code Documentation (2026b).
[9] Anthropic. “Agent Teams.” Claude Code Documentation (2026c).
[10] Anthropic. “How We Built Our Multi-Agent Research System.” Anthropic Engineering Blog (2025d).
[11] Anthropic. “A Harness for Every Task: Dynamic Workflows in Claude Code.” Anthropic Blog (2026d).
[12] Kim, Yubin, et al. “Towards a Science of Scaling Agent Systems.” arXiv preprint arXiv:2512.08296 (2025).
Citation
Citation: When reposting or citing content from this article, please credit the original author and source.
Cited as:
Yue Shui. (Jun 2026). How to Choose the Right Agent Architecture? https://syhya.github.io/posts/2026-06-21-agent-architecture-design
Or
@article{syhya2026-agent-architecture-design,
title = "How to Choose the Right Agent Architecture?",
author = "Yue Shui",
journal = "syhya.github.io",
year = "2026",
month = "Jun",
url = "https://syhya.github.io/posts/2026-06-21-agent-architecture-design"
}